
2025年10月14日,英伟达正式开始销售其DGX Spark“个人AI超级计算机”。
DGX Spark采用了英伟达Blackwell架构,搭载的GB10 芯片包含由 10 个 Arm Cortex-X925 核心与 10 个 Arm Cortex-A725 核心构成的 20 核 CPU,GPU 部分则拥有 6144 个 CUDA 核心,配备 256-Bit 128GB 的 LPDDR5x-9400 统一内存,FE 版本提供 4TB 固态硬盘。DGX Spark。DGX Spark单机拥有 1 petaflop 的 FP4 稀疏 AI 算力。
然而,不建议任何个人爱好者和中小企业购买DGX Spark,用来推理大模型。直接的原因就是其内存带宽极大的限制了模型推理输出速度。
知名大模型联盟组织LMSys,对于DGX Spark进行了评测。模型推理包括了GPT-OSS 20B和120B、Gemma 3的12B和27B、Llama 3.1 8B和70B、Qwen 3 32B、Deepseek R1 14B。可以说涵盖了各种尺寸的模型。
最残酷的一个问题就是,本地部署DGX Spark的费效比完全不划算。如果跑32B以下的模型,建议买RTX 5090,更便宜性能却更强;如果需要大显存,建议买RTX Pro 6000 Blackwell,价格贵2倍,性能提升5-10倍。他们的费效比都是更划算的。
| 型号 | 价格 | 点评 |
| RTX 5090 | 2000美元 | 32G显存,适合32G小体积模型,价格更便宜,速度快 |
| DGX Spark | 4000美元 | 128G内存,大提及模型推理速度极慢,小模型不如5090 |
| RTX Pro 6000 Blackwell | 8000美元 | 96G显存,价格高但速度提升10倍 |
DGX Spark开售之前,就已经知道一个明确的缺陷。由于采用LPDDR 5x内存,总的内存带宽只有273GB/s,远远低于GDDR7和HBM带宽,会严重限制输出速度。但SGLang测试的结果,还是差的出人意料。
下面这个表格,batch size表示并发数,batch size = 1表示只有一个用户发送了请求。prefill速度表示的是对于输入内容进行预处理,而我用红色框框框出来的表示decode速度是往外面吐token的速度。
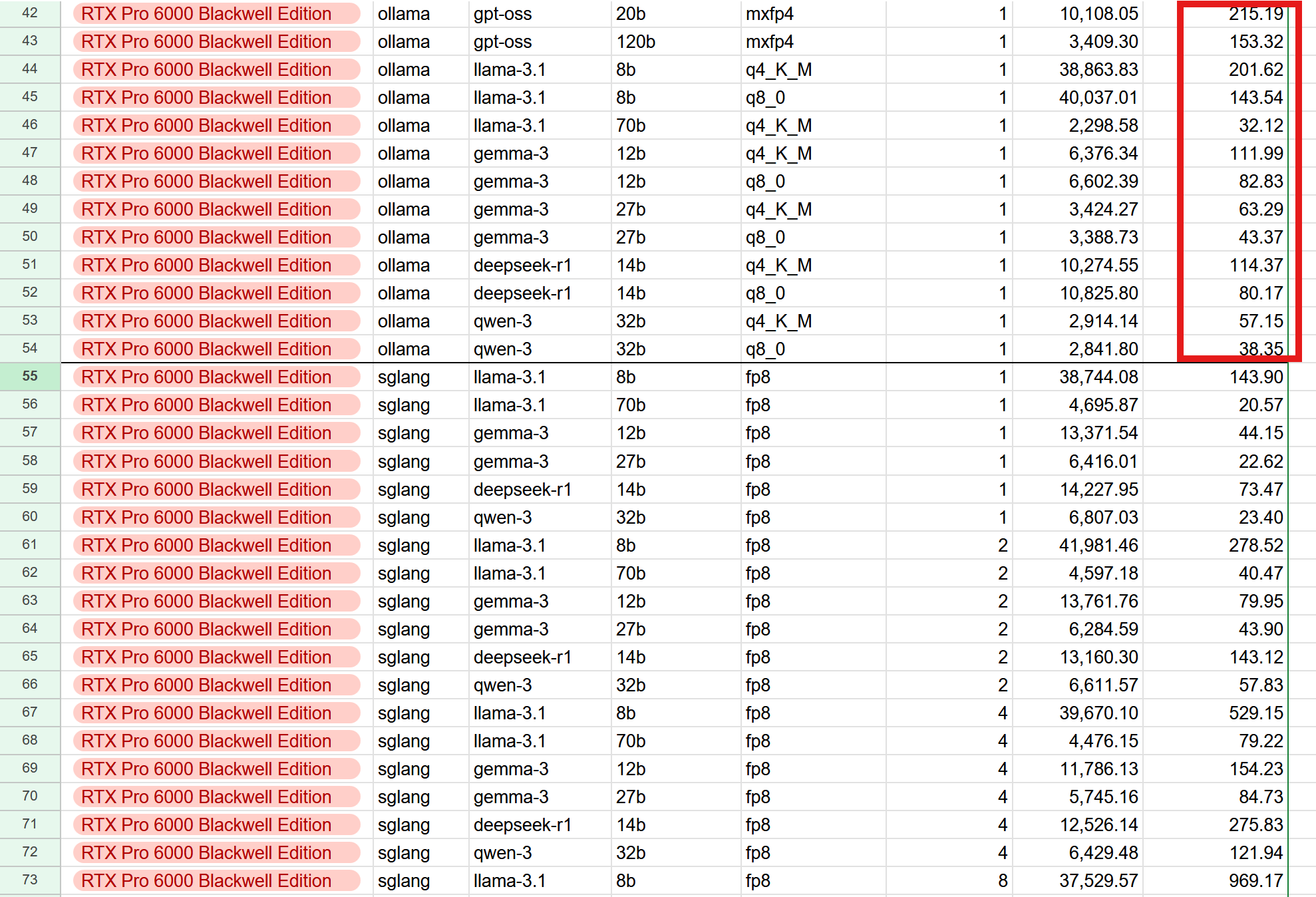
对于大体积的70B模型,输出速度只有4-5 token/s。速度最快的不到50token/s,是GPT-OSS-20B。

就个人用户而言,大体积的120B、70B、32B模型这种速度几乎没有什么场景下是可用的,个位数token/s,聊天、本地代码补全,这个速度都远远不够。20B和8B模型速度尚可,但那个买一个RTX 5090就能解决,为什么要多花钱来买DGX Spark呢?
DGX Spark能跑的最大体积的模型,是GPT-OSS-120B,这个模型价格在各大云服务平台百万token 1美元以内。4000美元机器成本,要跑40亿token才能打平。SGLang测出来,输出速度只有 11 token/s的速度来算,一天一刻不停最多吐100万token,一年3.65亿。你需要10年才能回本。
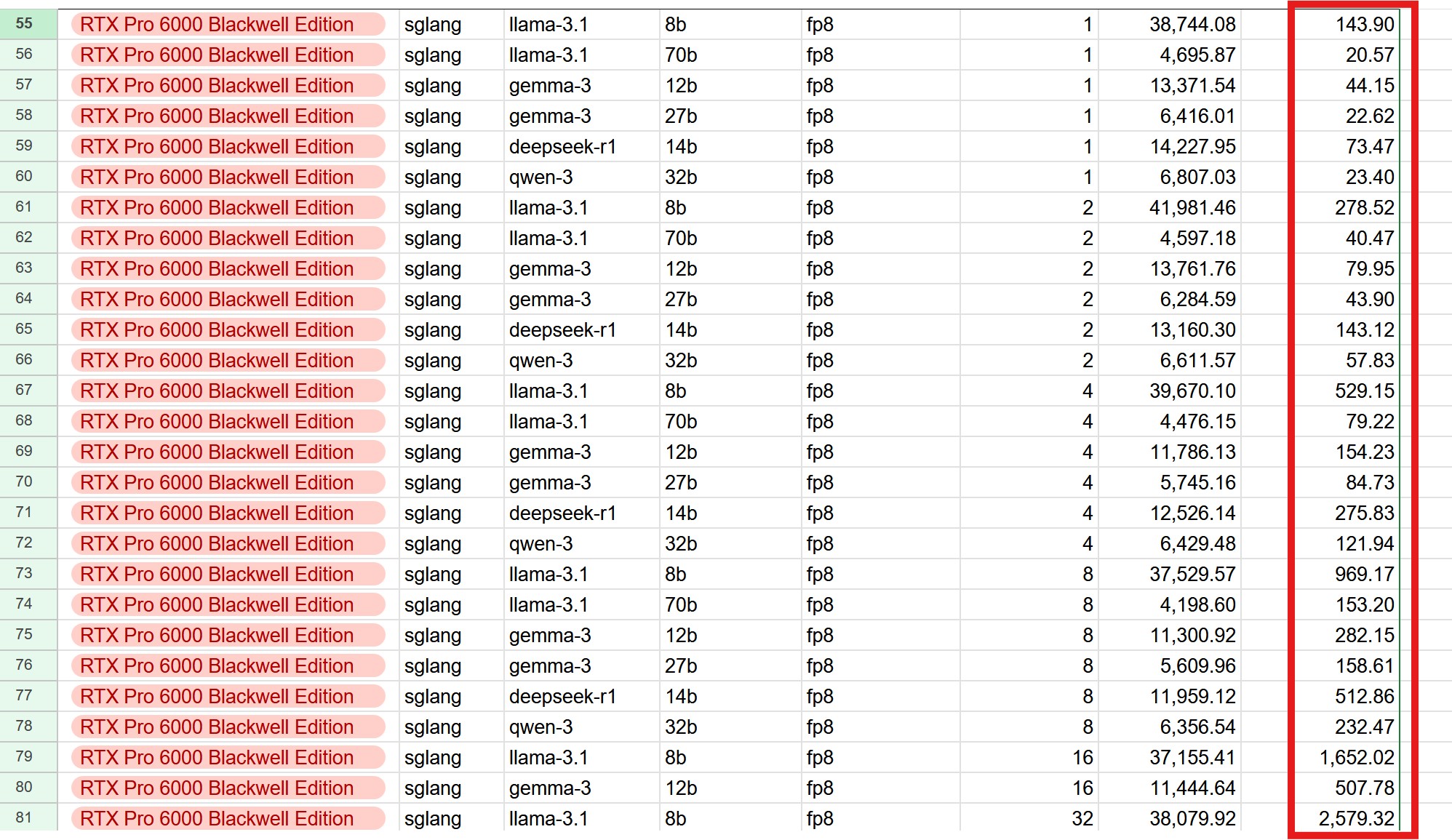
对于企业用户来说,可能会涉及到并发问题。SGLang也进行了测试,把batch size调大到最多32。给8B的模型,跑到32个并发,总输出368 token/s,单用户能体验到的速度只有10 token/s。一个8B的模型,跑这个速度也不值得骄傲。因为现在8B模型早就已经白菜价,不要钱了。

如果你要跑的模型,体积在32B以内,那么应该买的是配备32GB GDDR 7显存的RTX 5090。这样价格只有2000美元,立省一半,性能还更好。RTX 5090对付这些模型,输出速度能上百 token。
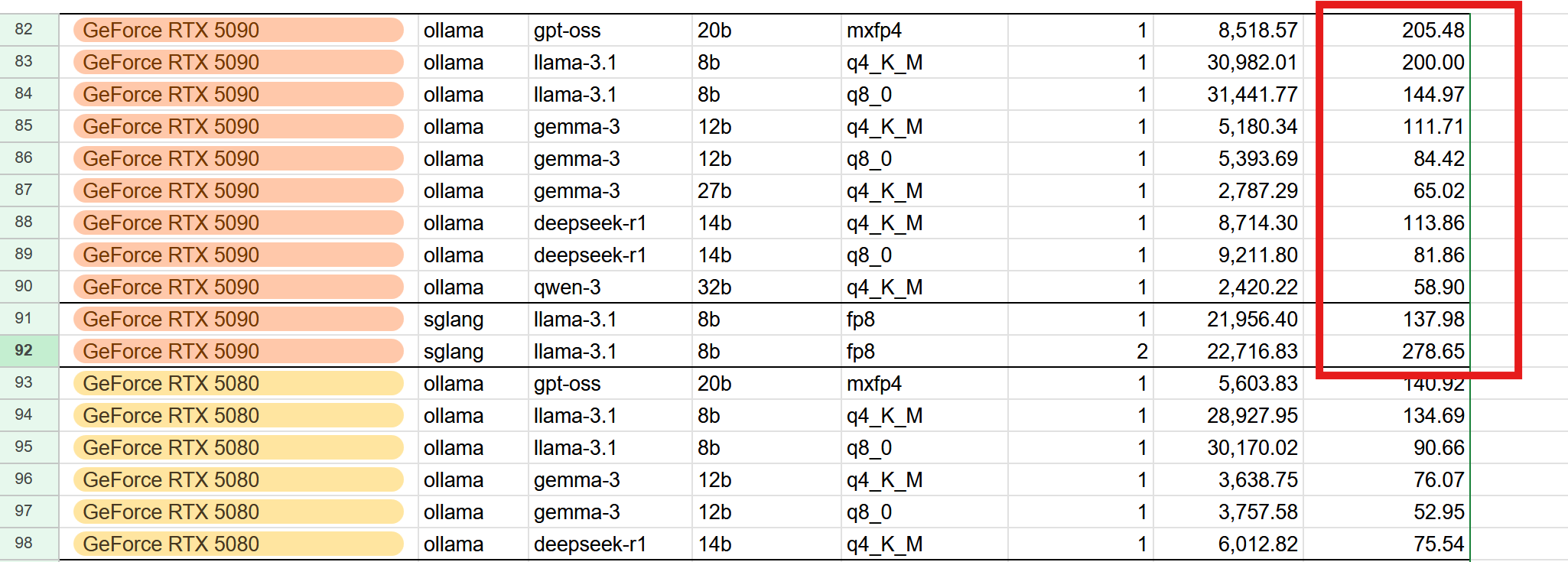
如果一定需要超大容量显存,那么应该买的是96GB显存的RTX Pro 6000 Blackwell。价格8000美元,是DGX Spark的2倍,但是性能提升是5-10倍的。
看企业并发场景下,32并发总输出2579,单个用户能到80 token/s。
LMsys组织旗下的SGLang,评测结果可以点击此处下载。
![]()