
AI PC最近火了。无论是芯片厂商Intel、AMD、Nvidia还是个人电脑厂商联想、惠普、戴尔,都在念叨AI PC这个词。
什么是AI PC?
网络上的AI PC定义非常繁多。AI PC的全称是Artificial Intelligence Personal Computer,意即人工智能个人电脑。AI PC最本质的定义,是能够在本地运行AI模型的个人电脑。
这里面有的关键词是本地运行——
由于大语言模型往往需要服务器集群进行推理,大多数AI服务都只能够通过云端运行,用户还需要付出订阅费用。最典型的是OpenAI旗下的chatGPT。而OpenAI的隐私条款当中也默认会将用户对话内容用于模型训练,存在一定的隐私泄露风险。
AI PC则强调能够在本地运行,主要优势是可以在无网络环境下使用、本地运行更加注重保护用户隐私、无需订阅费用。
AI应用大爆发
2023年是人工智能真正意义上爆发的一年。早期所谓的人工智能能力有限,仅仅能做到图片和文本的识别与分类,由此诞生出来的例如语音助手等应用场景,常常被称为“人工智障”。
2023年以来,AI工具由被动响应转向了主动创作(AIGC, Artificial Intelligence Generated Content):chatGPT展现出了惊人的能力,能够回答问题,在常识、编程、逻辑推理、创意输出方方面堪称全能手;stable Diffusion可以根据用户的简单提示词,生成精美的画面。

因此,让AI能够“赋能”个人电脑,也就成为整个PC行业的下一个风口和共识。
AI PC和普通PC的区别:模型量化、专用NPU、GPU与NPU协同
严格来说,在2023年也有个人电脑能够在本地运行大语言模型——例如在台式机端,你有一个RTX 4060Ti 16GB显卡,就能够运行chatGLM 6B的模型。不过,这种运行方式仅限于少数高配置的台式机,只是少数爱好者与极客的玩具,普适性不足。
从2024年开始的AI PC,更强调普遍可用的AI能力,让大多数笔记本电脑也能够跑起AI应用程序。AI PC的主要实现方式,将会是模型量化、专用NPU、GPU与NPU协同运行。
- 模型量化已经是低成本运行大语言模型的行业通行做法。
如果以不做量化的BF16格式,6B参数(60亿参数)的模型就要占用6*2=12GB内存或显存,推理运行还需要占用更多内存。而如果量化到INT 4,则需要6/2=3GB;量化到INT 8,仅需6GB即可。
现阶段市面上在售的大多数笔记本电脑搭载16GB或32GB内存,而搭载独立显卡的游戏本显存容量则是RTX 4050的6GB、RTX 4060的8GB为主。如果不做量化,无论是内存还是显存,都存在吃不消的情况。量化后的3GB和6GB,则意味着大多数游戏本运行本地模型,至少从显存上来说不存在瓶颈。
- NPU:矩阵运算加速。
大语言模型和文字生成图片的预训练模型,计算时涉及大量的矩阵运算。如果采用CPU进行运算,需要将矩阵的行列相乘、相加过程拆分开来,运行效率极低。GPU通过大量的处理单元并行计算,提高速度。
专用NPU则通过专门电路设计,将矩阵运算一次性完成,功耗低,效率高。这也就是所谓的ASIC (Application specific integrated circuits),专为大语言模型运算设计的芯片电路。
- NPU与GPU协同运算。
英特尔以Stable Diffusion为例,阐述了NPU和GPU协同运算的优势,速度更快,功耗相对可接受。
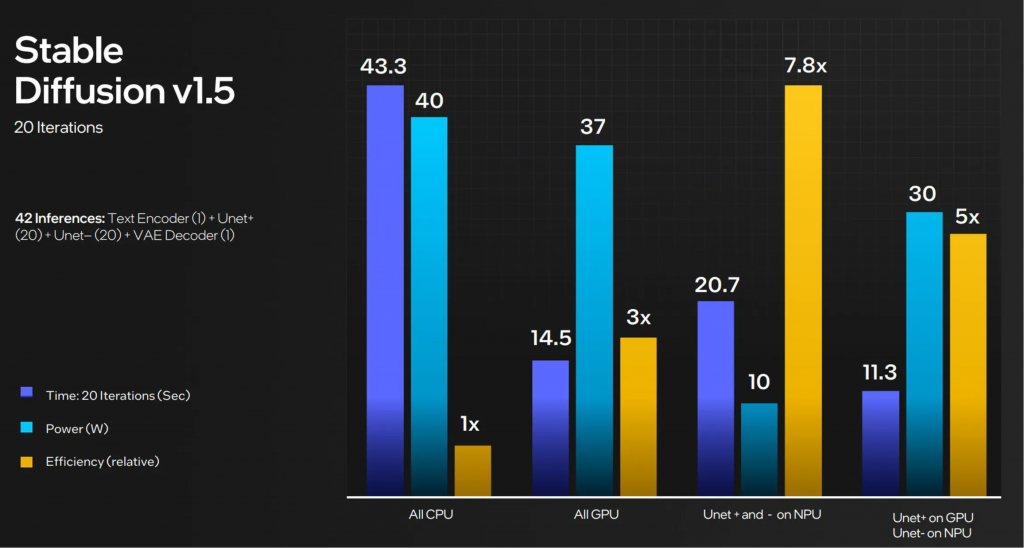
这也意味着,2024年的AI PC,将有很大一部分通过厂商预装AI模型的预训练权重,以便本地推理。
AI PC主要模型:中国将以chatGLM为主
AI PC由于需要在本地搭载模型,海外将以LLaMA为主,而中国区受限于监管规则,各家将会以chatGLM为基准。
LLaMA 2由Meta开发,开源了7B、13B、70B不同大小规格的预训练模型权重,供全社会免费使用。如果用过LLaMA 2的用户就会发现,用中文直接向LLaMA提问,LLaMA能够理解问题但回复内容为英文。不过LLaMA由于输出内容不可控、对于中文支持不好的情况,将会在海外大面积搭载,国内想要搭载或许还有一定的难度。
chatGLM作为质谱AI旗下的产品,其6B版本(60亿参数)的预训练模型权重是开源的。目前chatGLM已经迭代到了第三代,也即chatGLM3。其官方宣称要做到10B参数的小尺寸模型最强。chatGLM通过了网信办备案,也是目前中文支持最为完备的小尺寸开源模型之一。
AI PC悖论:本地模型能力不足,为什么不用在线的呢?
尽管AI PC概念火热,但是笔者不得不提出一个本地运行模型的悖论:消费者为什么要用本地的模型呢?
自从chatGPT全球火爆之后,大多数AI服务都以在线运行为主,运行在云端,运行在本地的AI并不多。
究其根本原因,在于目前本地运行的开源模型能力不足。对于大语言模型来说,消费者存在“只用最好”的倾向。例如GPT 4和Claude 2就能够一次提问解决问题,而如果是chatGLM-6B可能只会车轱辘话来回说,难以得到有效信息。久而久之,消费者就会直接转向GPT 4和Claude 2,而不是先用本地模型。
也有人提出例如概括文本这样的任务看似简单,可以在本地模型解决。但这样的想法未免幼稚,真正使用体验过就知道,想要概括得好仍然需要模型具备很强的基础知识。模型有多少智能都不够用的。
而对于大多数用户来说,隐私并不是一个大问题。本地模型能力不足的先天缺陷下,仅凭借隐私、安全,很难在消费者市场立足,难以打动广大用户。
闭源模型和开源模型之间,能力存在代差,这也是当下AI PC面临的最大悖论与挑战。当前2023年,个人电脑出货量已经跌至COVID-19之前的水平(参见本网数据库持续追踪)。AI PC对于整体PC行业的提振作用,或许没有想象中那么大,笔者在此表示谨慎乐观。
宏观视角:AI PC算力分散,减轻云端压力
或许从另一个视角来看,AI PC的合理性也就得到了解释。当前不少AI服务都需要用户付费使用,根本原因就在于云端AI模型运算成本高企。
在本地的AI PC大规模上市之后,通过调用本地算力,即可缓解云服务器厂商的算力压力。从这个角度来说,AI PC更像是一个权宜之计,避免云端算力压力增长过快。
![]()