2022年12月发布的ChatGPT,引爆了全球新一轮AI热潮。如今的大语言模型LLM需要海量互联网数据进行训练,网站、博客无不被纳入到了其训练数据集当中。
网站被AI爬虫访问是双刃剑——
- 如果网站内容被纳入了大模型的训练数据集,那么其思想就会成为大模型内在知识的一部分。Perplexity、ChatGPT、Claude也逐步接入了搜索功能,网站内容如果被 AI 频繁引用,影响力也在增强。训练和搜索是网站AI影响力的两大部分。传统意义上的搜索引擎优化SEO,逐步转向了生成式引擎优化GEO。
- AI爬虫激增,占用服务器响应、带宽等宝贵资源。一些网站不堪其扰。
为什么可以作为样本?
笔记本电脑评测网后台的AI爬虫,提供了极佳的观察窗口。笔记本电脑评测网是专注于垂直内容的中小型网站,以独家内容、显卡天梯图、数据库整理、行业信息汇总为特色。
从相关访问量数据来看,JetPack组件统计,每月真实访客量10,000。来自谷歌搜索控制台Search Console数据显示,每28天点击量为1,500;必应WebMaster每30天点击量为3,700。每月网站后台出流量80GB-100GB。笔记本电脑评测网的robots.txt没有对任何爬虫加以限制。
AI爬虫解析
笔记本电脑评测网统计了2025年12月8日到2025年12月13日之间主要AI爬虫的访问量数据,计算增量和日均爬取量。站长纳入了OpenAI、Anthropic、CommonCrawl数据集的爬虫。
| Bot | 2025年12月8日 | 2025年12月13日 | 5天增量 | 日均爬取 |
|---|---|---|---|---|
| ChatGPT-User | 49,477 | 52,483 | +3,006 | ~601/天 |
| GPTBot | 30,353 | 30,534 | +181 | ~36/天 |
| OAI-SearchBot | 17,447 | 17,687 | +240 | ~48/天 |
| ClaudeBot | 27,088 | 27,471 | +383 | ~77/天 |
| CCBot | 1,396 | 1,450 | +54 | ~11/天 |
| Claude-User | 6 | 6 | 0 | 0 |
OpenAI和Anthropic在其官网有明确的爬虫说明文档。例如OpenAI官网文档就明确了,GPTBot是用于训练数据采集的,ChatGPT-User代表用户访问网站获取内容,OAI-SearchBot则用于搜索。Anthropic官网帮助中心同样说明了三种类似的爬虫,ClaudeBot训练、Claude-User代表用户、Claude-SearchBot用于搜索。
CommonCrawl则是一个大型开源训练语料库,其爬虫被标记为CCBot。
值得一提的是,相比于上述明确标识爬虫的AI公司,也有其他公司的做法很不规范。例如谷歌并未明确标识用于Gemini模型训练的爬虫,而只有混用其搜索业务的Google Bot,站长需要通过Google-Extended字段来控制是否允许将被抓取内容用于训练未来 Gemini 模型/以及用于 Gemini/Vertex AI 的 grounding 等用途。
中国国内大模型厂商如Deepseek、Kimi、GLM并未在官网标注其爬虫的User Agent,无法纳入分析。这是极不专业、极不负责的做法。
爬虫汇总结果
从数据汇总结果来看,OpenAI的爬虫在5天统计期内,每天平均有685次访问。Claude爬虫日均仅为77次访问。从按照公司归属来看,OpenAI的体量远大于Anthropic。
| 公司 | 5天总增量 | 日均 |
|---|---|---|
| OpenAI (ChatGPT-User + GPTBot + OAI-SearchBot) | +3,427 | ~685/天 |
| Anthropic (ClaudeBot + Claude-User) | +383 | ~77/天 |
| Common Crawl (CCBot) | +54 | ~11/天 |
但是,OpenAI绝大多数访问量为ChatGPT-User代表用户读取内容,达到了每天600次。而用于训练的GPTBot仅为每天36次。Anthropic旗下来自于Claude用户发起的请求几乎可以忽略不记,大多数爬虫则来自于训练目的的ClaudeBot,达到了每天77次,甚至爬取频率是GPTBot的2倍。
换而言之,OpenAI的ChatGPT用户基数庞大,爬虫绝大多数都在为了用户服务。而在模型训练的抓取频次上,Anthropic力度则比OpenAI大得多。
具体爬取内容
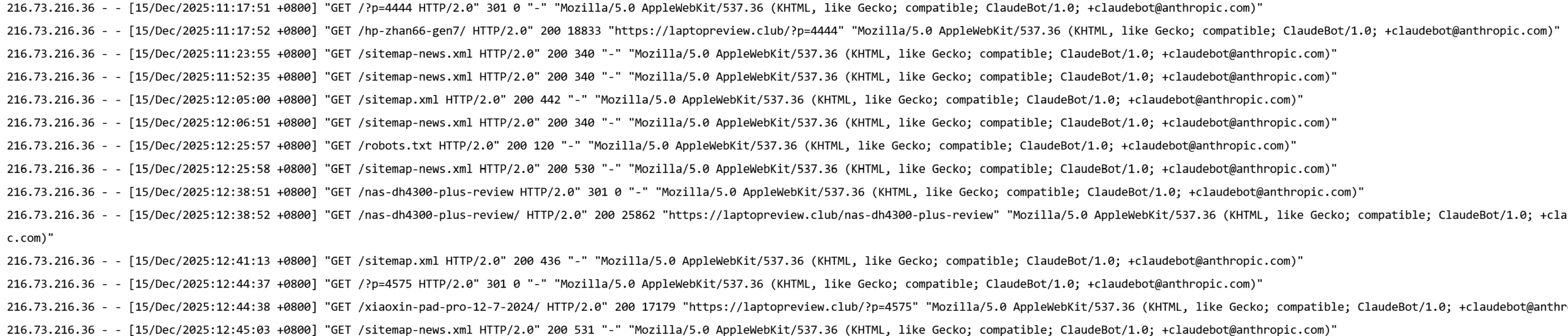
站长在后台具体查看了两家爬虫不同的行为特征。ClaudeBot会频繁抓取robots.txt协议,查看是否允许抓取。同时,会选择高频抓取sitemap-news.xml,以查看网站是否有更新。其抓取sitemap-news.xml的频率几乎是达到了每2-3小时访问一次。
216.73.216.36 – – [15/Dec/2025:12:06:51 +0800] “GET /sitemap-news.xml HTTP/2.0” 200 340 “-” “Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)”
216.73.216.36 – – [15/Dec/2025:12:25:57 +0800] “GET /robots.txt HTTP/2.0” 200 120 “-” “Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)”
而OpenAI的模型则没有体现出高频抓取sitemap-news.xml的特征,抓取网页相对更加多元。
笔记本电脑评测网在2025年12月8日发布了微型计算机产量数据库,OpenAI和Anthropic的爬虫在发布后3小时内即进行了抓取。
74.7.243.131 – – [08/Dec/2025:17:40:11 +0800] “GET /china-micro-computer-production-database/ HTTP/2.0” 200 22691 “-” “Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)”
74.7.243.131 – – [08/Dec/2025:17:40:25 +0800] “GET /china-micro-computer-production-database/ HTTP/2.0” 200 22691 “-” “Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)”216.73.216.19 – – [08/Dec/2025:22:52:04 +0800] “GET /china-micro-computer-production-database/ HTTP/2.0” 200 23897 “https://laptopreview.club/china-micro-computer-production-database” “Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)”
216.73.216.19 – – [08/Dec/2025:23:36:26 +0800] “GET /china-micro-computer-production-database/ HTTP/2.0” 200 23897 “https://laptopreview.club/?p=5676” “Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)”
不过爬虫行为在12月8日和9日抓取后,后续就不再进行抓取。而一直到文章发布一周后,CommonCrawl数据集的爬虫并未进行抓取。这显示出闭源模型两大厂商,仍然有着更强的数据抓取能力。
预告
笔记本电脑评测网的爬虫报告,后续将持续更新。相关内容被AI前哨转载评述。
![]()