传统意义上,舆论都有这样的论调——美国擅长基础研发,中国擅长做应用和落地。但大模型时代,“中国大模型擅长落地和应用”只是一种幻觉。美国头部公司OpenAI、Anthropic,无论是应用功能丰富度、API功能都明显领先,而且两大巨头呈现出明显的纵向整合迹象。
美国大模型公司超级巨头的野心
首先回顾互联网时代,美国诞生了众多的细分SaaS公司,而中国则诞生了超级应用。
以餐饮业为例,美国的餐厅官网有SquareSpace,点评由Yelp,订座由OpenTable,在线点餐有Square(和前面做官网的SquareSpace虽然名字相同,但不是同一家公司),外卖有DoorDash。而不同的SaaS服务之间还可以有API互联互通,例如在官网可以设置专门的链接到OpenTable,也可以接入Square和DoorDash。
而中国的餐饮业,美团承担了官网、订座、点评(大众点评也是美团旗下的)、外卖、在线点餐的几乎所有业务,甚至还开了美团月付,进军支付领域。纵向垂直整合之后,超级应用也就诞生了。用美团,几乎就可以解决中国几乎一切餐饮问题。
互联网时代,美国不同的SaaS公司保持一定程度的“克制”,只深耕自己领域内的一亩三分地,通常不会随意扩张到其他领域。但大模型时代明显不同——OpenAI、Anthropic呈现出明显的行业扩张迹象。
- OpenAI每一次的开发者大会都会被戏称为“消灭开发者大会”,在2025年10月的开发者大会上接入了Agent Builder,很大程度上挤压了Dify、Coze、n8n这些下游应用的生存空间。
- Cursor在代码领域深耕,是Anthropic的下游开发者和大客户。但Anthropic却主动推出Claude Code这样的Coding产品主动出击,只用3个月时间就达到了5亿美元ARR,快速超过Cursor做了2年时间才达到的5亿美元ARR。
这表明,大模型时代的两家领先初创公司,并不满足于只做一家基础模型的提供者,而更愿意在上下游做进一步扩展,把自己打造为超级巨头。无论OpenAI还是Anthropic,他们的ARR分别达到130亿和50亿美元,体量上都已经不容小觑了。
ChatGPT是超级应用:功能最丰富,用户心智最强
过去两年时间,虽然很多人号称要做AI应用和落地。但纵观国内产品的功能丰富度,能够超过ChatGPT的确是一个都没有。
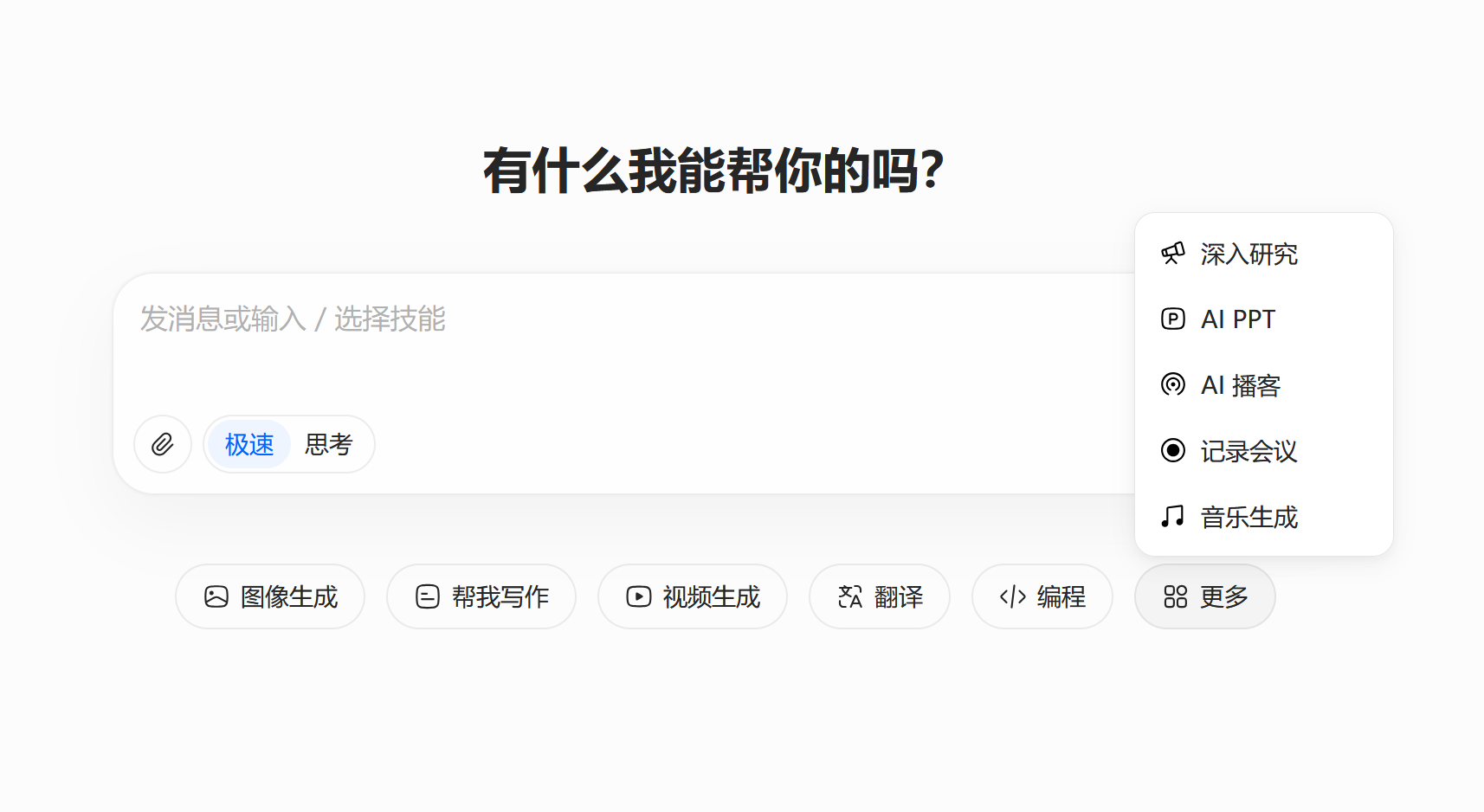
目前仅仅是在ChatGPT以图标呈现的功能,就已经提供了附件上传、连接器、深度研究、Agent模式、创建图片、网页搜索、画布、研究和学习。此外ChatGPT还支持数据分析、Code Interpreter在线代码运行、quiz flashcard、Codex、会议记录模式,后台还支持用户自定义指令,提供了Memory,面向更高阶的Pro用户又支持Pulse每日简报。
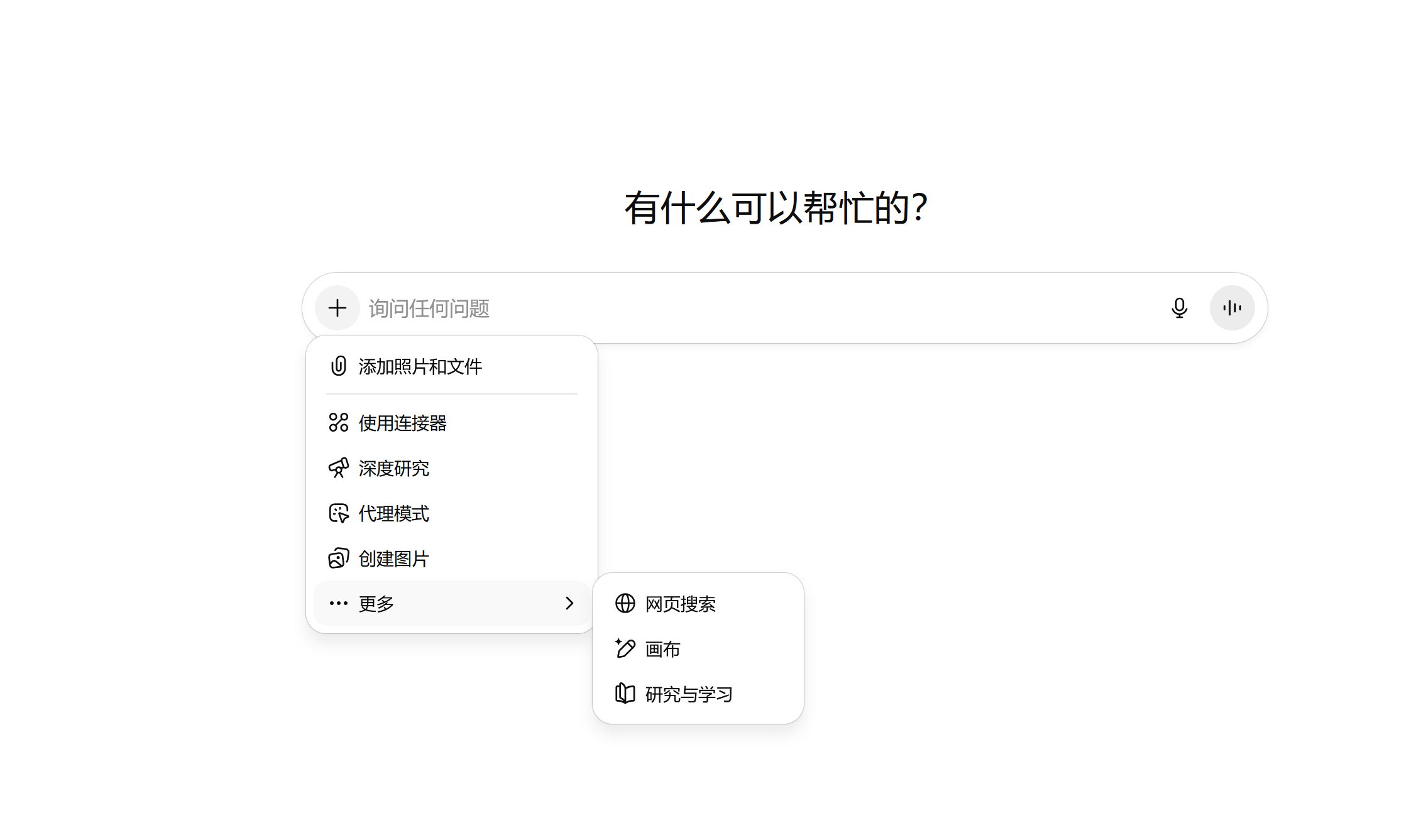
而作为对比国内日活第二的Deepseek,仅支持附件上传、联网搜索、深度思考三个功能。
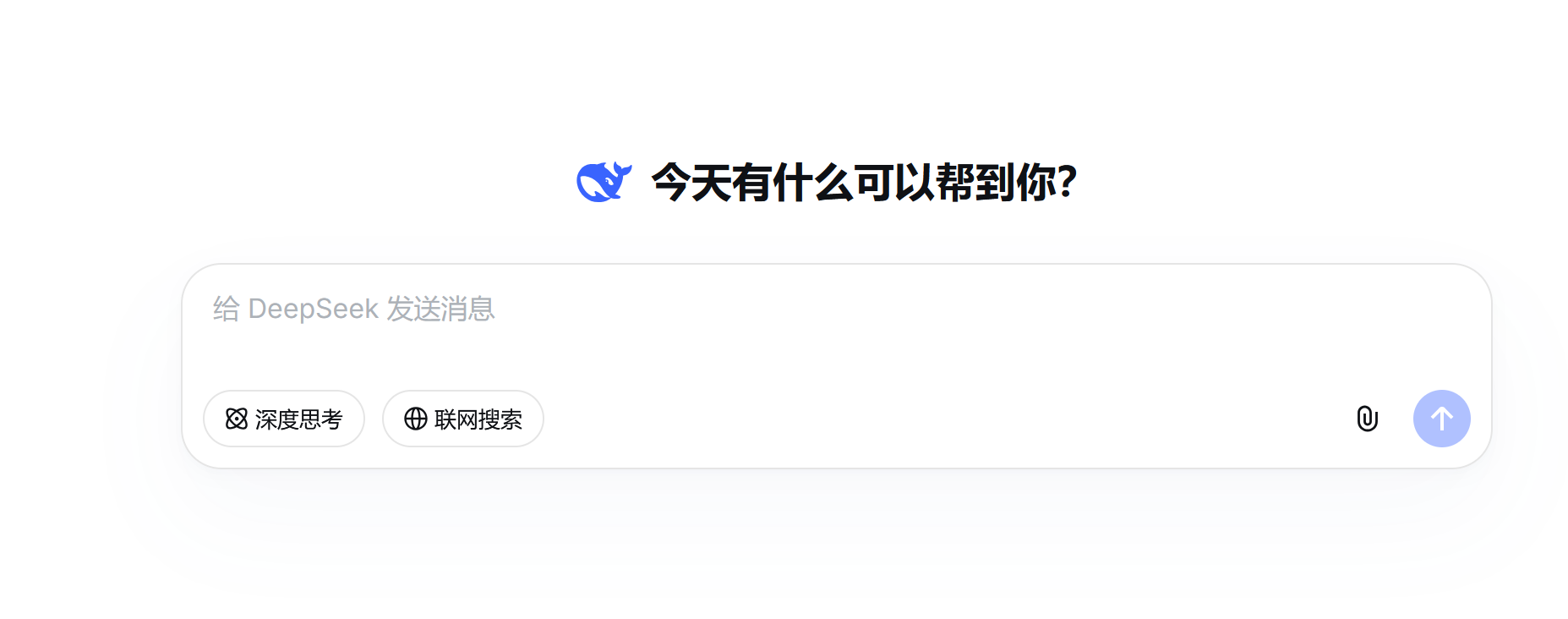
豆包才是中国国内应用功能最丰富的应用,也能看到他步步紧跟ChatGPT功能更新的步伐。深入研究、会议记录、支持code interpreter容器、编程接入了Trae,都是跟着ChatGPT模仿而来的功能,AI PPT属于国内特色,AI播客则是抄来了Google NotebookLM的功能。
豆包初期并不成功,就是因为战略失误押错了赛道,选择细分情感陪伴赛道,走在模仿Charater AI的路上。这导致豆包的用户增长在早期十分乏力。
豆包AI模仿的Charater AI本身就是一个失败典型,Charater AI至今月活不超过3000万,无法变现,创始人卖身回归谷歌。同期ChatGPT则逐渐涨到了8亿周活。ChatGPT基于8亿用户发布的使用报告,披露不足1%的用户用于情感陪伴,表明这一赛道本身容量有限,远不及ChatGPT的通用聊天机器人场景大。
豆包后续回归主流通用Chatbot赛道,丰富功能,才回归强劲增长。但即便是今天全方位学习ChatGPT并试图整合更多功能的豆包,功能丰富度上相比于ChatGPT也没有绝对优势。
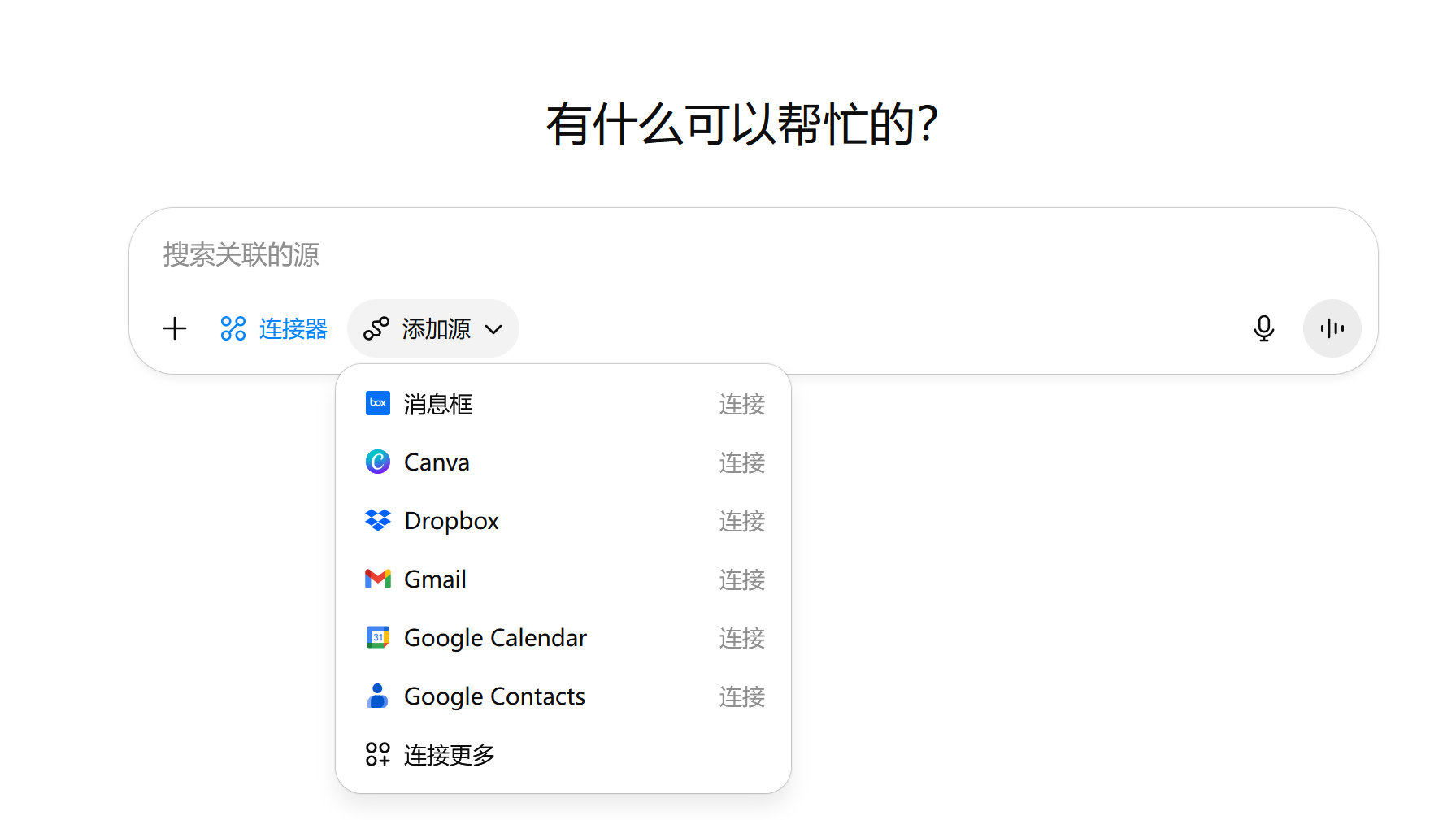
而值得注意的是,虽然ChatGPT在打造超级应用,但依然保持了美国SaaS上一个版本的优势——互联互通,并没有走向中国移动互联网“不联不通”“各自为营”的局面。通过连接器,依然可以链接Gmail、日历、Dropbox等其他产品。
切莫沉浸在上一个版本“中国擅长应用”的幻觉当中。目前ChatGPT是功能最丰富的AI原生应用,也是用户量最大的超级应用,这一点是无可争议的。
ChatGPT目前年化订阅用户已经超过了3000万,企业版500万付费,200美元一个月的Pro可能也超过了50万,年度订阅的会员费就能收100亿美元,比那些标榜自己是做AI应用加起来都要多。
API功能:国内明显欠缺
相比于ChatGPT这类AI应用程序,面向开发者的API则和“落地”相关。如果仔细对比的话,你就会发现,中国国内的大模型API提供的功能丰富度远远落后于OpenAI、Anthropic。
- OpenAI已经支持到了Responses API,保留状态、更好的工具调用支持。而绝大多数国内的API仍然停留在兼容OpenAI Chat Completions API,需要自己手动拼接上下文和聊天历史。

- OpenAI的API平台,支持function calling,而中国国内头部大模型Deepseek至今思考模式不支持工具调用。本来API当中提供function calling和tool use就是方便用户直接走专门的工具通道,现在Deepseek却需要用户自己倒退回正则表达式字符串匹配取出对应的工具调用,严重影响效率。

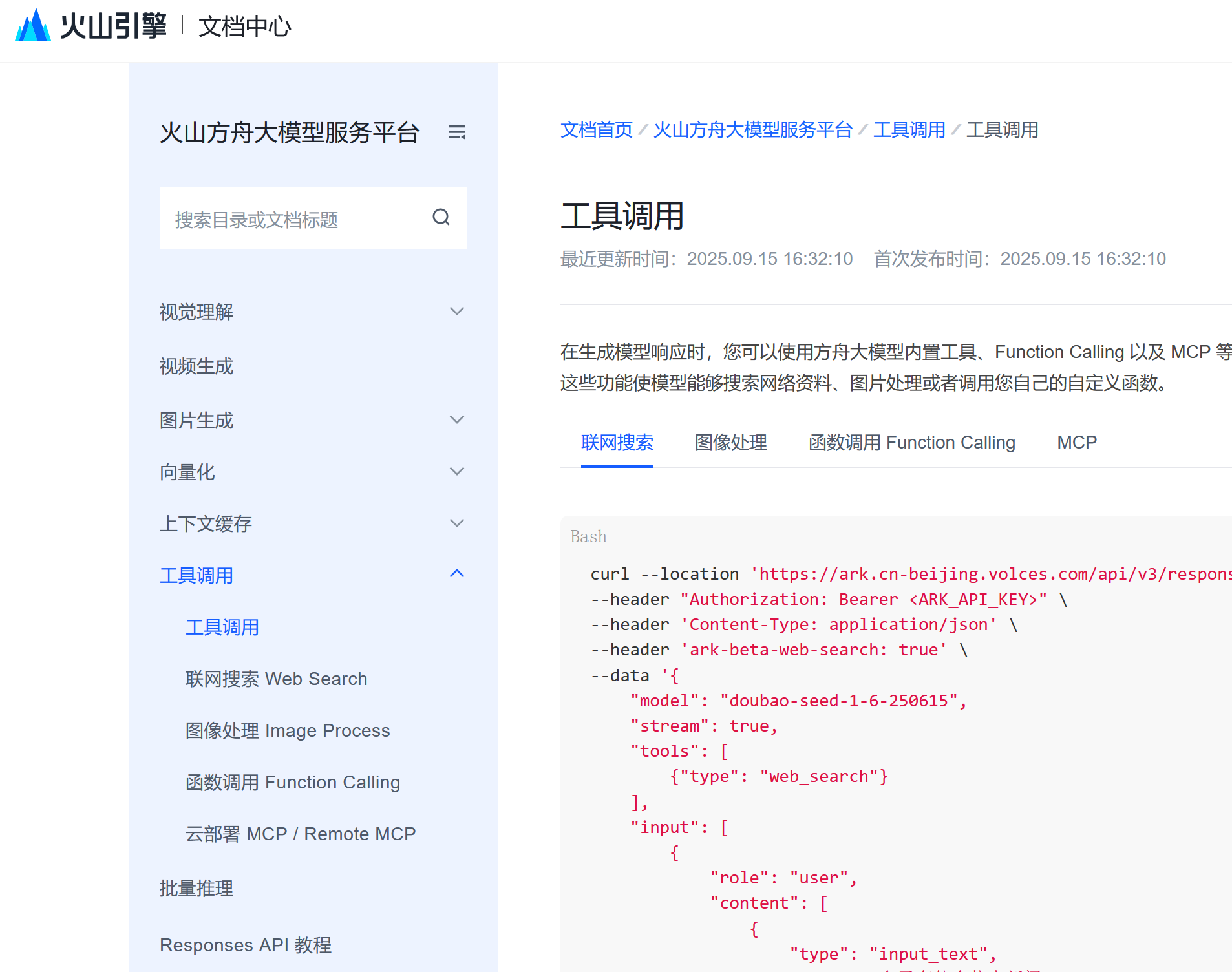
- OpenAI API平台里面直接开启web search,支持code interpreter在容器当中运行代码,支持文件搜索,支持自主连接MCP服务器。OpenAI都已经原生提供了丰富的工具,不需要开发者重复造轮子,对比中国国内没有几家云服务推理商支持web search API,支持容器代码运行,支持方便的文件搜索。

虽然中国开源模型可以有第三方任意托管,但例如硅基流动仍然停留在算力解决基础推理的生存线上,并未做出更加丰富的功能,API非常原始,甚至不支持缓存折扣。这导致Deepseek官方API结合缓存命中仍然是性价比最高的。

当然,这里表扬的同样是字节。字节的火山引擎,已经开始支持Responses API,已经开始接入web search,但似乎并没有开放container做code interpreter。
在这里再次强调,国内备受吹捧的to B和to G私有化部署,绝不是AI应用和落地的主流。本轮LLM浪潮是纯to C的ChatGPT引领,企业的接纳受制于安全、保密、隐私和流程,反而非常缓慢。不存在to B就高人一等。美国公司不少还停留在llama 2模型,中国国内不少所谓的私有部署其实是Deepseek Distill 32B。养老院里诞生不了创新,to B落地现阶段事实上远远落后于消费者能够直接使用到的模型。
正如同Character AI的细分赛道,绝对不会超过ChatGPT的通用场景,私有化部署也是一个比ChatGPT和公有云API低1-2个数量级的场景。
如果说API的功能方便与否,还能通过自己写正则表达式解析模型输出,实现工具调用。那么国内常说的“落地”则和模型的微调分不开。模型通常都要针对场景进行微调优化,才能够融入到生产场景当中。一边说落地,一边不提供微调服务,本身就是精神分裂的存在。
而目前GPT 5的微调已经在beta测试当中,OpenAI官网就能提供GPT 4.1系列的微调。而国内提供微调的云服务商则寥寥无几。
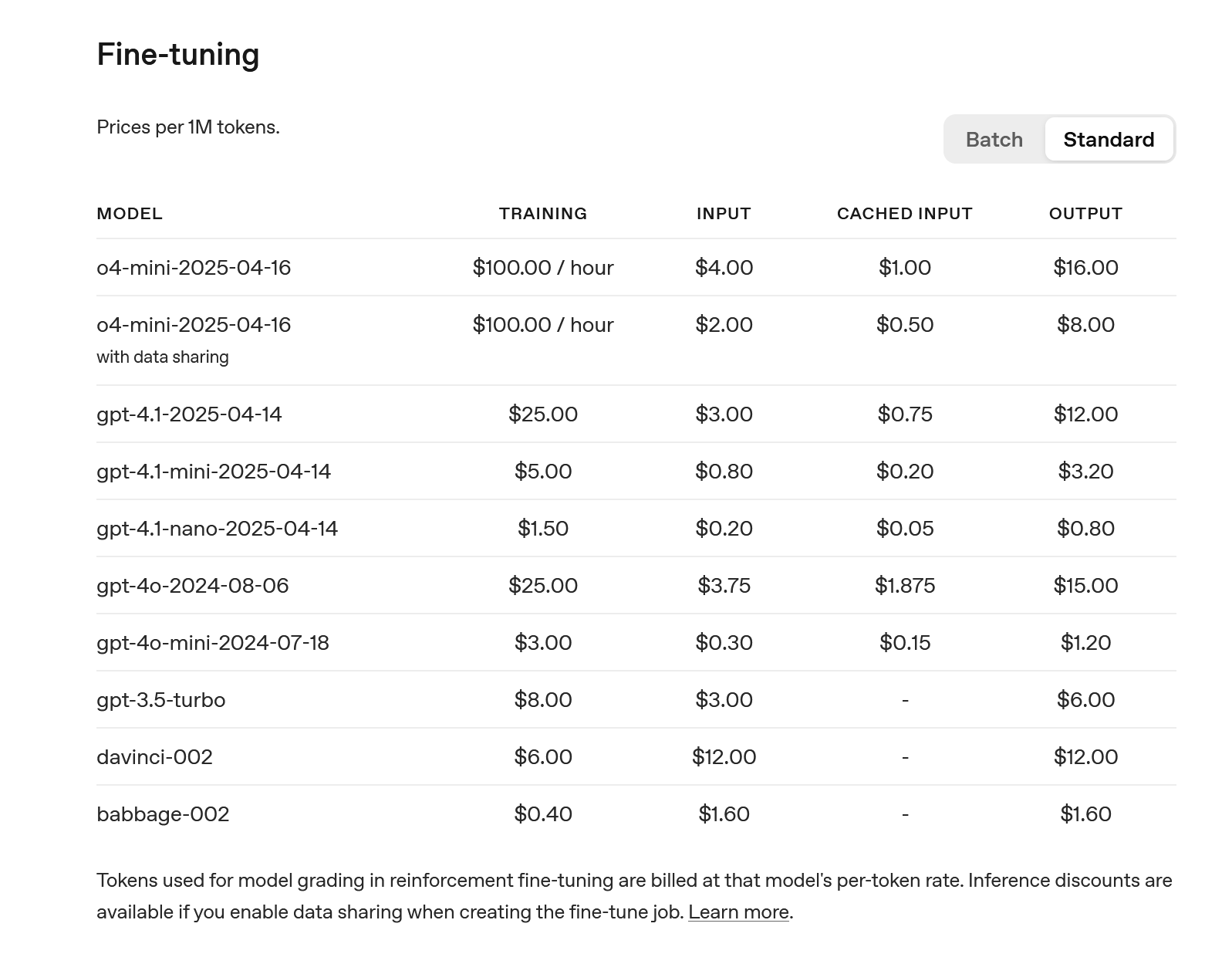
例如硅基流动,只支持到Qwen 2.5系列。
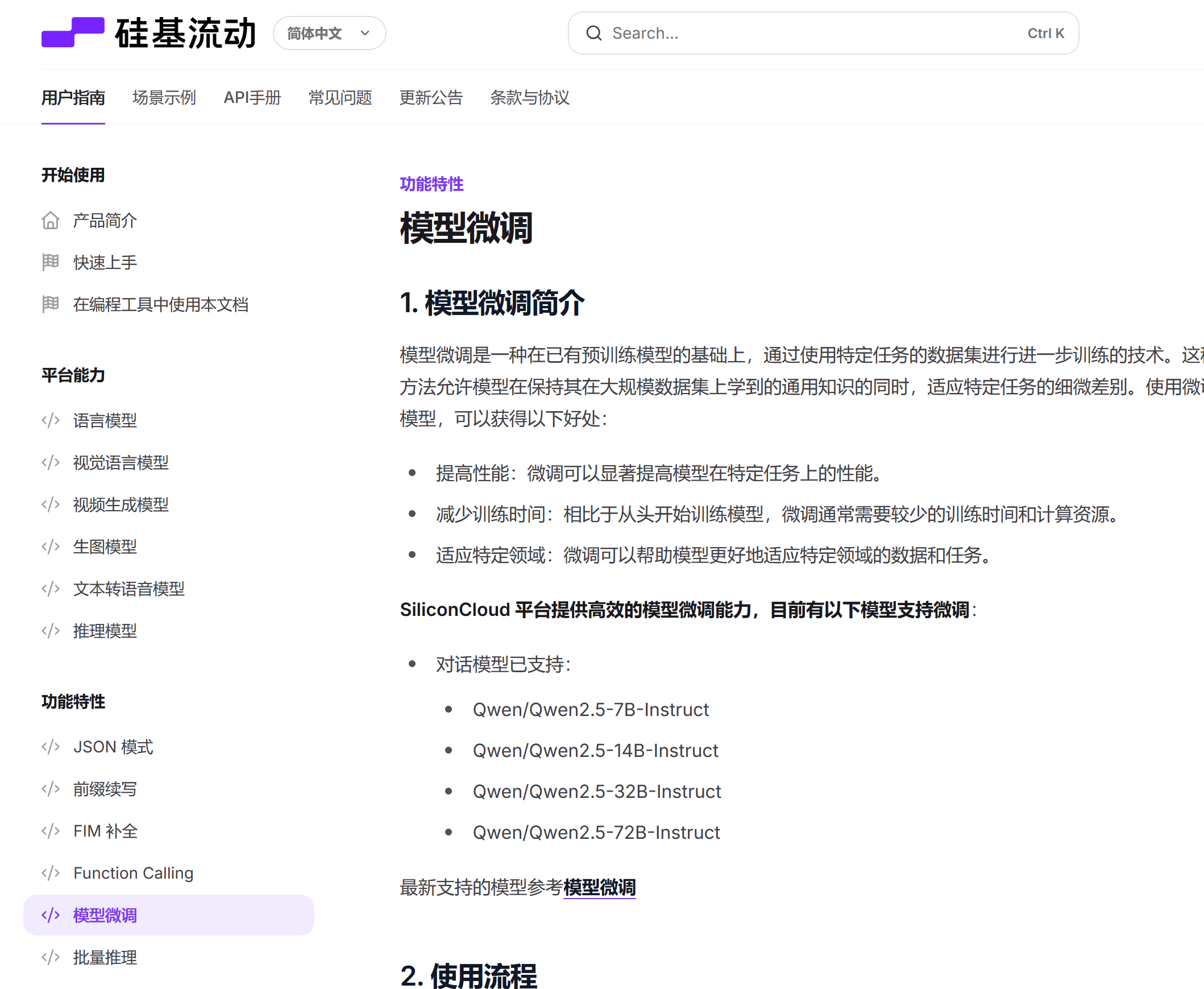
字节火山方舟只支持2个2025年1月发布的模型。
应用和API丰富度,绝对不可小觑
本文写于2025年10月13日,在应用功能丰富度、API支持上对比了国内和海外的区别。至少在当下这个时间节点上,ChatGPT有着最丰富的应用功能,Anthropic和OpenAI的API功能比国内平台更加丰富。更可怕的是在应用层面的丰富度,不少人还沉浸在移动互联网时代的美梦下,恐怕只是一种幻觉。
![]()