很多人好奇,为什么不能用CPU做大模型的推理。大多数数据中心都在使用显卡GPU做大模型推理。
CPU本地推理,仅供个人玩家单个并发试水玩一玩性质的,解决的是“以最低限度能跑起来”。CPU单并发慢,更无法满足高并发场景。如果算费效比,CPU推理也并不划算。
CPU推理比显卡欠缺在两点,一个是显存带宽,一个是算力。
大部分CPU推理都用DDR内存,带宽相比于GPU用的GDDR和HBM显存,速度会差1个数量级。LLM生成token的时候需要读取激活的模型参数,是memory bound被显存带宽约束的。DDR内存读取速度更慢,会导致单并发速度缓慢。你注意看那些用CPU推理671B Deepseek,速度都只有10 token/s,完全没法用的。
有人说现在的MoE模型,每次只需要激活一部分参数,比如Deepseek的671B只激活37B,岂不是利好吗?但这仅限于单个并发,涉及到多个请求,就会同时激活多组37B参数,迅速吃满DDR内存带宽。
其次是现在英伟达的显卡推理用FP4这样的低精度算力,比CPU高了2-3个数量级。这使得多个请求并发的时候,CPU的算力资源被迅速耗尽。
之前一直苦于没有一个很好的例子,来直观展示纯CPU推理和有GPU场景下的性能差距。最近正好找到了MLPerf Inference里面有各大机构提交的数据中心服务器推理速度,其中正好有厂商用了同型号的Intel Xeon 6787P 处理器,分别提交了带显卡和不带显卡的速度。评测模型是llama 3.1 8B。
- 在offline场景下,请求一次性发送。8卡RTX Pro 6000 Blackwell的,能够达到46,841 token/s,不带显卡的CPU推理是819 token/s,两者的差距是50倍。
- 如果用更能反映真实负载的Server场景,把请求数按照泊松分布发送给服务器,RTX Pro 6000 Blackwell的性能几乎没有降低,而CPU推理则降低到257 token/s,差距扩大到179倍。
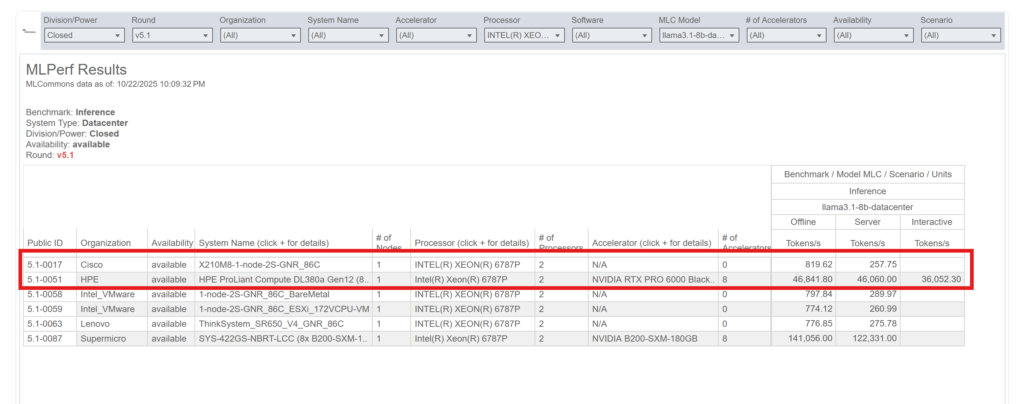
纯CPU,英特尔至强6787P配上大内存的服务器,本身报价就会超过2万美元。RTX Pro 6000 Blackwell单卡报价是8000美元,8卡就是6万美元。这意味着如果你买了8卡RTX Pro 6000 Blackwell,只需要付出3倍的价格,就能够享受到50-179倍的性能。
这也是黄仁勋所说的“你买的越多,省的越多”(the more you buy, the more you save)的真实体现。
![]()