
Rubin CPX,是专门为推理阶段prefill准备的低成本卡。
名字里的Rubin,说明他采用的架构和下一代Rubin GPU数据中心卡一致。但CPX的128GB显存是GDDR 7做的,和游戏卡保持一致,而不是数据中心计算卡常用的HBM。这就是CPX最大的区别。
GDDR 7当然要比HBM的速度慢。
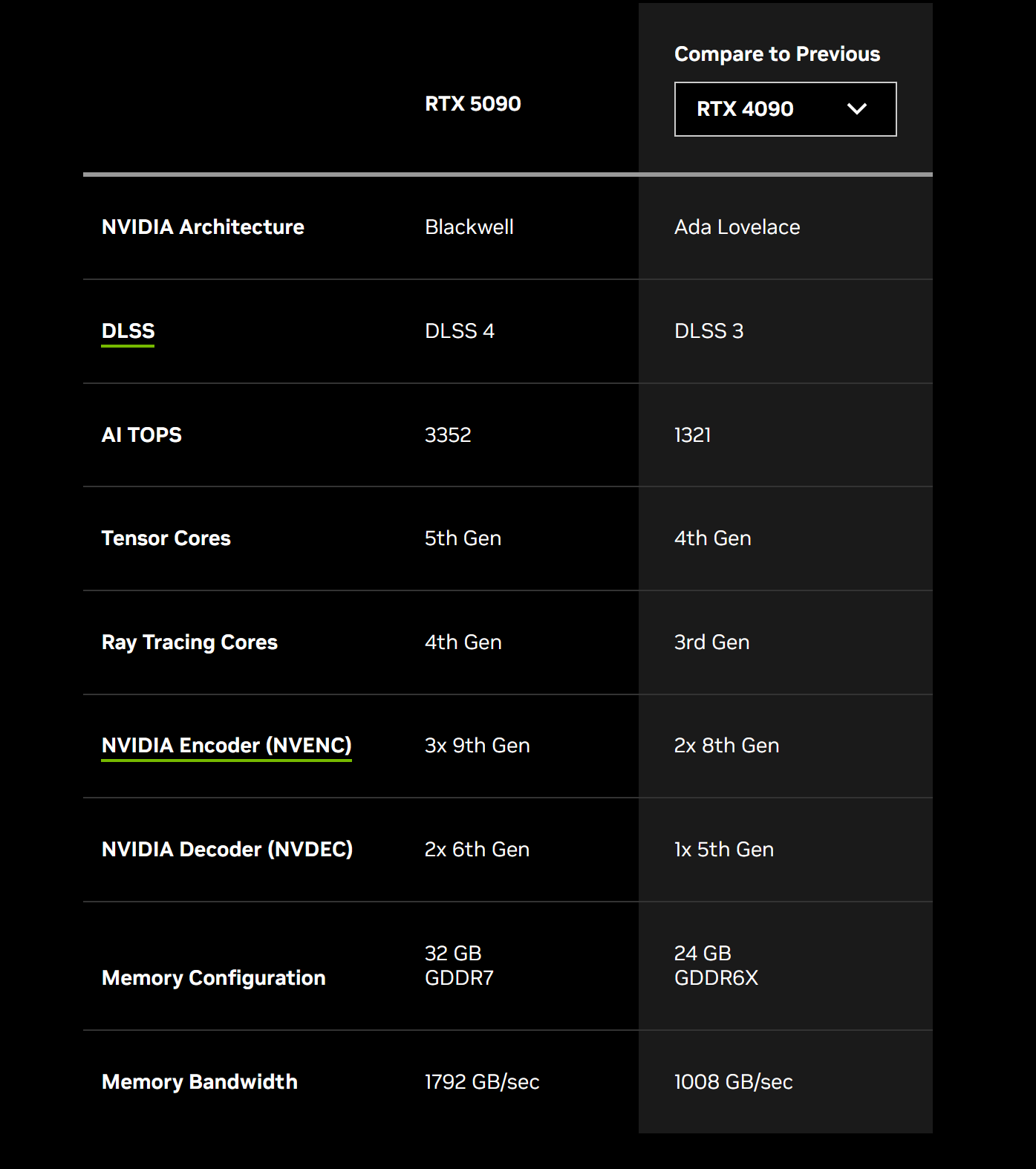
现在以RTX 5090为例,GDDR 7显存的带宽是1.8 TB/s。作为对比,采用了HBM 3e的B200和B300,显存带宽是8TB/s。
考虑到CPX是Rubin属于下一代显卡,到时候HBM会从现在的3e升级到HBM 4。根据 海力士量产HBM 4新闻稿 ,带宽还要再翻一倍。
所以到时候的Rubin的正经GPU采用HBM 4会达到16TB/s,而Rubin CPX推理卡采用 GDDR 7 只有 2TB/s 的带宽,差距接近10倍。
GDDR 7显存带宽低带来的好处,是成本降低。
数据中心的高速显存HBM,价格至少是民用游戏显卡GDDR 7显存的3倍左右。CPX可想而知成本不会特别高。
推理的过程,prefill就是对输入进来的上下文进行填充,决定了首个token蹦出来的时间,是一个compute bound的任务;而decode则是生成新的token,每次新生成都需要遍历模型权重,是一个memory bound吃显存带宽的任务。
CPX如果算力方面不砍,只是把显存给换了,可以服务于prefill阶段。
新闻稿里面铺天盖地都强调支持1M,其实128GB显存在数据中心卡当中并不算特别大。如果你是营销号、复读机,那就只会重复百万上下文,不谈就背后的原因是什么。其实潜台词是CPX价格会便宜,多买一点,就支持超长上下文的prefill了。

现实世界当中,我也不同意有些人说的decode比prefill价值高的说法。我用Claude Code是一次随便什么任务都起码输入20K token,所以prefill的上下文依然是非常重要的。
NVL 144 机架,配比怎么办?
由于prefill和decode两大阶段都不可或缺,所以英伟达也推出了NVL 144 CPX机架。在单个主板上,集成2个英伟达的Vera CPU,4个Rubin GPU,8个CPX,通过Connect X-9连接在一起。
这个问题来了,现实世界的工作负载的比例是不确定的。假设CPX做prefill,Rubin GPU做decode,中间的KV Cache通过传输解决,他们的配比不一定是正好1:2。
在主板上集成了固定配比的Rubin GPU和CPX,但硬件固定的配比使用起来就不够灵活。

所以我个人理解,最后这种1:2的配比,需要OpenAI这样的模型厂商在设计模型架构的时候就预先考虑到,最终实际workload才能够正好切配比。
![]()