2023年11月13日,英伟达在官网发布了H200 GPU,并公布了相关的规格。相比于不少媒体又将其称为史诗级进步不同,笔者认为H200是一个“小”升级,同时是整个AI行业由训练走向推理的一个标志性节点。
- 英伟达的H200 GPU是一个“小”升级款,核心计算单元规格不变,换用了HBM3e的显存,显存带宽提高,同时将显存容量从80GB提高到了141GB。
- H200更多是为推理而生,训练方面提升不大。
把H100 SXM和H200 SXM规格表放在一起比较就知道了,这两个AI芯片的算力是一模一样的,只有显存、带宽发生了改变。
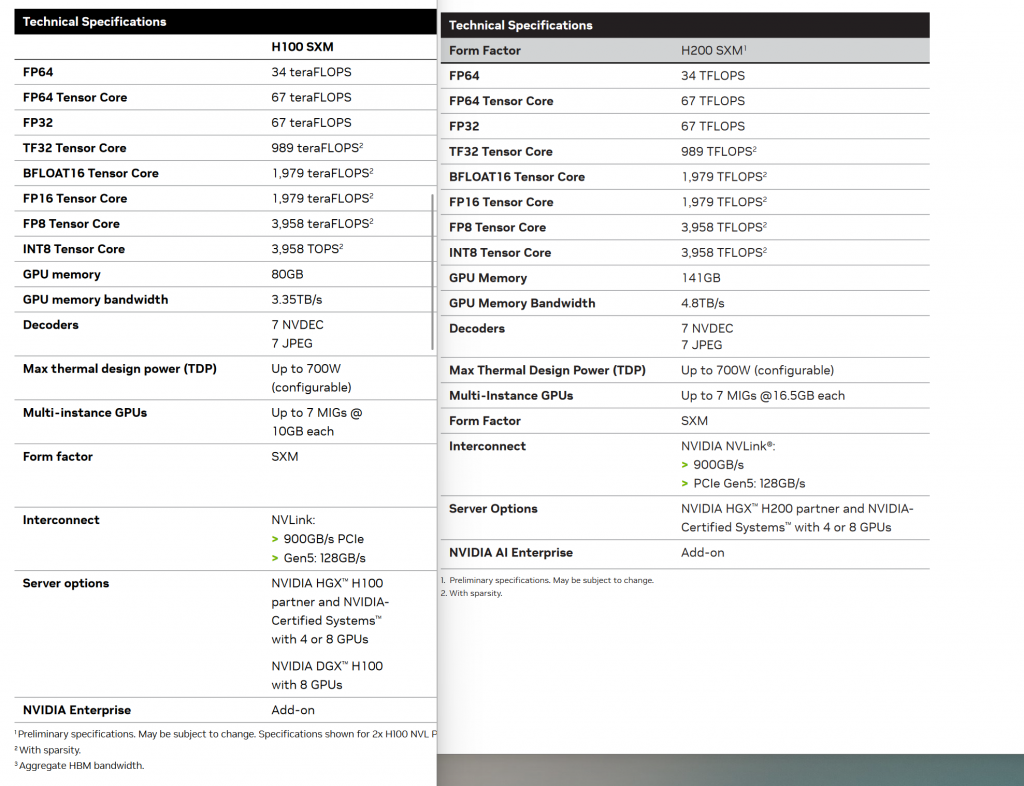
因为H100用的是HBM3的显存
HBM3 memory subsystemprovides nearly a 2x bandwidth increase over the previous generation. The H100 SXM5 GPU is the world’s first GPU with HBM3 memory delivering a class-leading 3 TB/sec of memory bandwidth.
到了H200变成了HBM3e显存
NVIDIA H200 is the first GPU to offer 141 gigabytes (GB) of HBM3e memory at 4.8 terabytes per second (TB/s)—that’s nearly double the capacity of theNVIDIA H100 Tensor Core GPUwith 1.4X more memory bandwidth.
至于说HBM3E显存哪来的?产业链成熟了,海力士早就有HBM3E,三星也来了,美光也做了。参见相关行业报道。
随着AI大语言模型的大规模应用,任务中心也就从训练模型,转向了推理。而H200提升了显存带宽和容量,没有提高“算力”,所以提升更多在推理方面。
你看英伟达这个标题,是Inference速度,推理速度,不是训练哦。
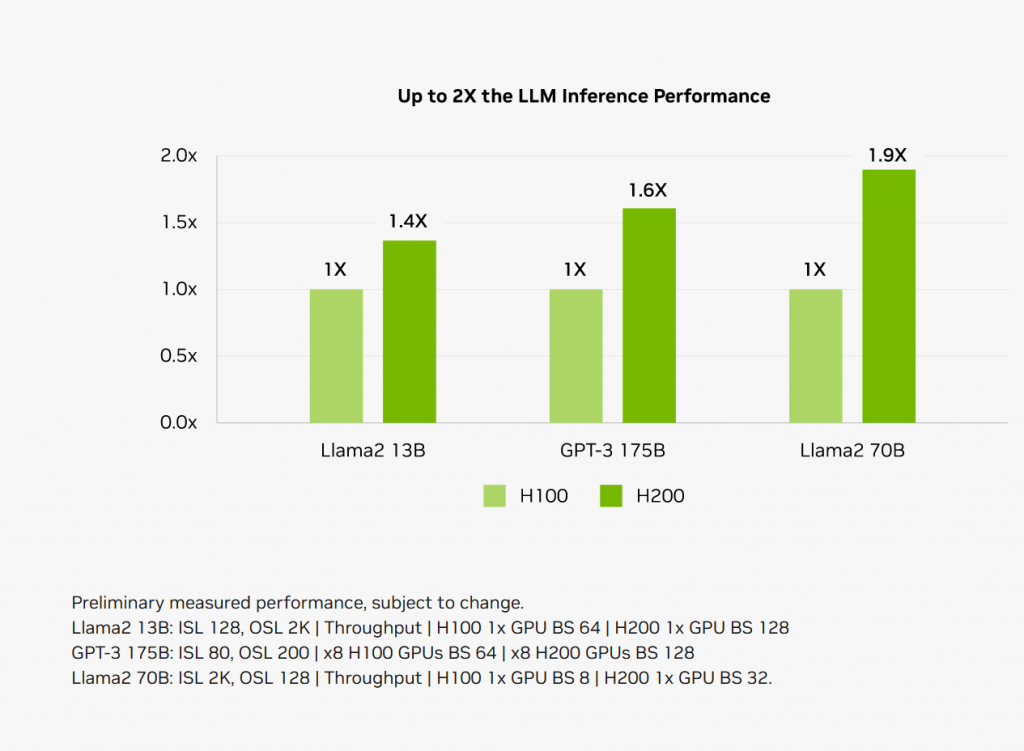
因为一般而言,推理集群算力不是瓶颈,而是被显存带宽和单个GPU显存大小给卡着。比如一旦出现跨GPU的互联,虽然说有NV Link,但是跨卡通信速度900GB/s和单个GPU内部的4.8TB/s也差了一个数量级。单个GPU的显存容量提升至后,跨卡访问的次数也就减少了。
所以,像H200这样显存容量大幅度提升的情况……这也验证了笔者的一个观点,那就是大语言模型推动了大容量显存的需求之后,后续计算卡的显存容量会快速提高。
例如游戏卡的显存抠抠搜搜,归根结底是没有需求,除了个别搞深度学习的专业用户,打游戏真的是8G显存相对够用了。现在有了可以在本地运行AI推理的应用场景,未来RTX这类卡显存翻倍应该都是可能的。
未来甚至算力和游戏性能不强,但是专门主打大容量显存的消费级显卡会越来越多——大语言模型能不能跑,比跑起来究竟是20token一秒还是30Token一秒重要多了。换句话说,游戏玩家视之如粪土的RTX 4060Ti 16G产品定义风格的产品会越来越多。
本网站之前也介绍过利用RTX 4060Ti 16G的大容量显存优势运行大语言模型的案例,可以阅读相关文章。
资料:NVIDIA H200 Tensor GPU Datasheet参数表,本网站下载镜像
![]()