一、前期环境准备
1. 硬件配置
本次模型训练基于YOLOV5模型。本人计算机硬件配置为英特尔12代酷睿i9 12900H、32G内存容量、无独立显卡的联想YOGA Pro14s 2022款,因此参照的是CPU版本的训练方法。
在实测中,CPU版本运行速度尚可,完成100轮训练耗时约20分钟,推理耗时约为100ms左右,在可以接受的范围之内。相比于GPU版本的CUDA软件下载时间较长、版本配置较多,CPU版本作为教学演示可能更为合适。
2. 软件准备
使用Anaconda创建名为yolov5的专用环境。 关于anaconda的使用方法,可参照网络其他教程。请注意一定要在anaconda安装过程中勾选环境变量,避免后续手动添加环境变量的麻烦。
YOLOV5模型从Github下载yolov5-master软件包并进行解压,下载网址链接。如果不使用git clone命令,在Github网址中下载zip压缩包是最好的选择。
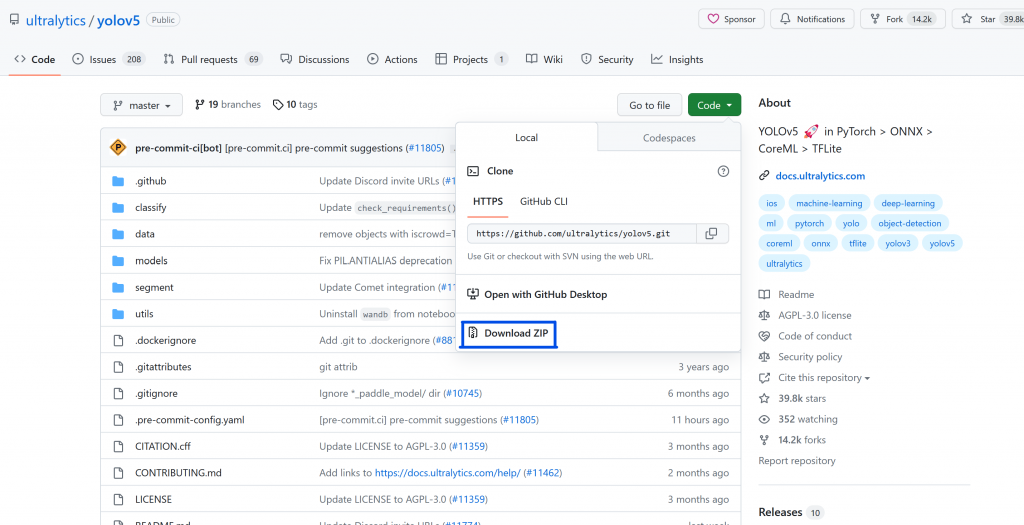
在yolov5-master所在的文件夹地址栏输入cmd并敲击回车,即可在当前目录下进入命令行环境。在命令行中输入activate yolov5即可启动专用环境,输入pip install -r requirements.txt,即可自动配置。
由于yolov5自带的requirements.txt文件当中即为CPU版本的tensor,因此本次训练无需做额外更改。
二、数据集准备
1. 图像收集
本次训练所基于的数据集,均来自于网络。使用百度图片,搜集了互联网上戴口罩和不戴口罩的相关图片。
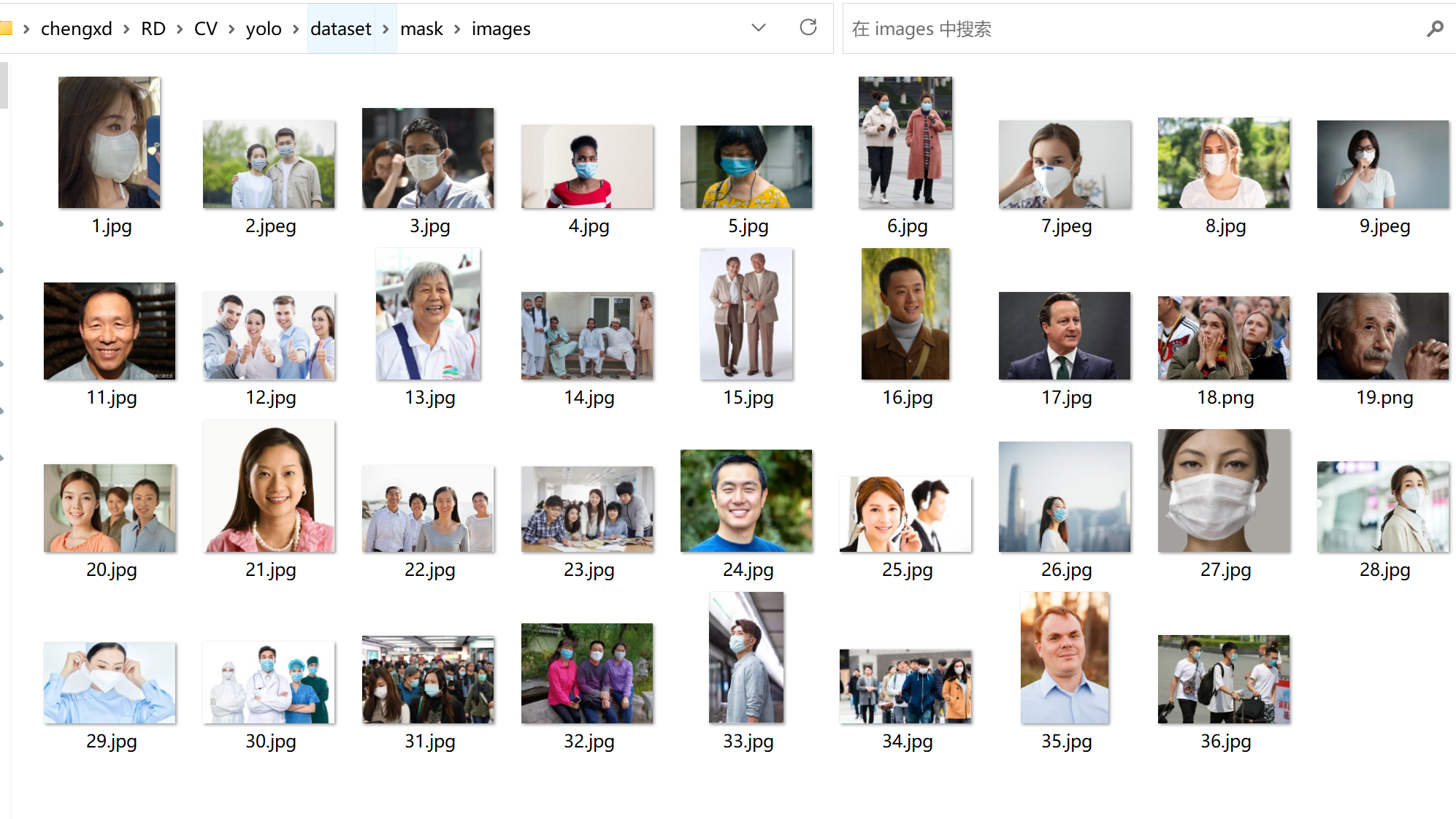
2. 图像标注
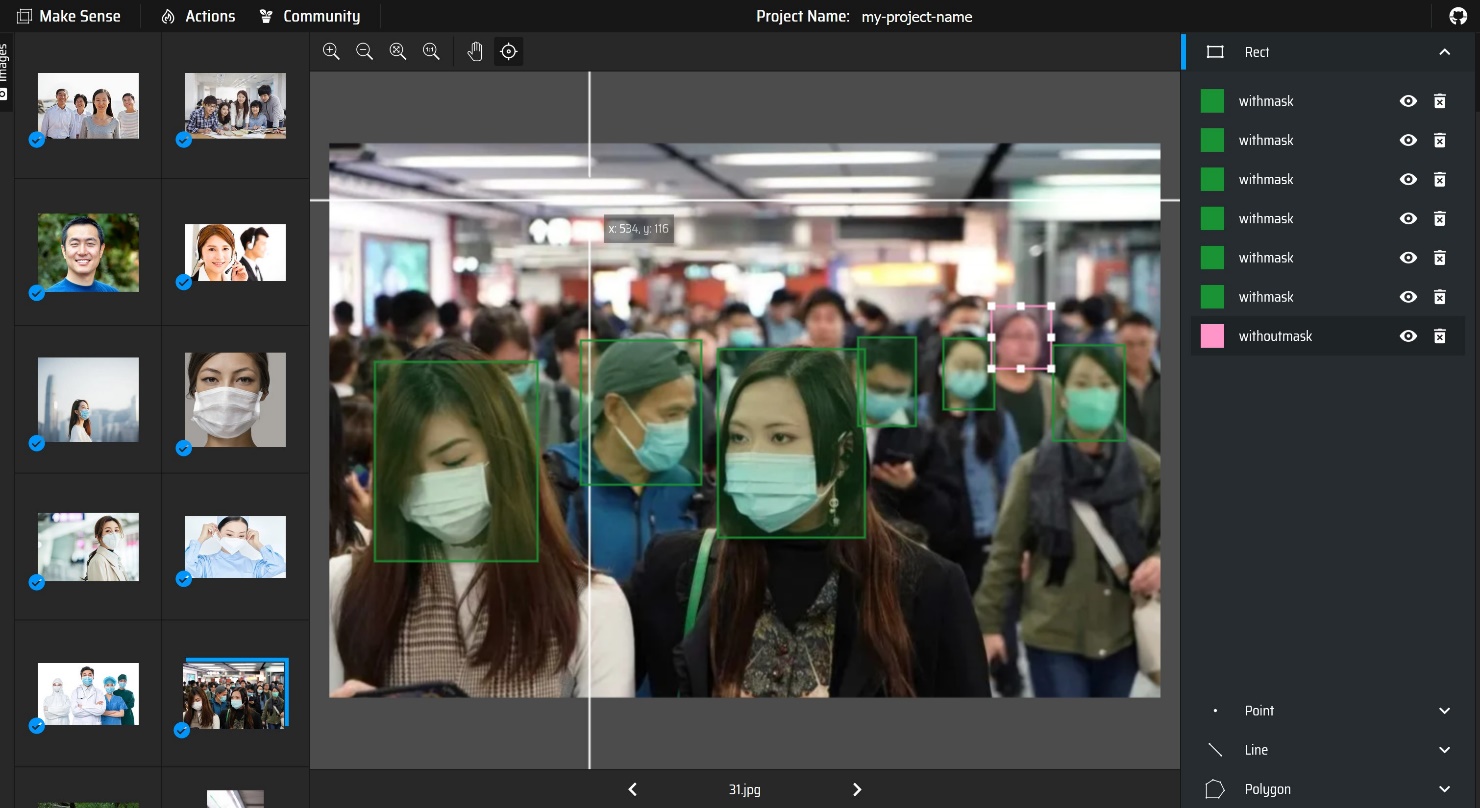
将图片上传到makesense.ai网站进行标注,网址。
makesense.ai是一个在线网页打标签的工具,可以用于图像标注、目标检测等任务。该工具支持多种标注类型,包括点、线、框等,同时也支持多种标签导出格式,如YOLO、VOCXML、VGG JSON、CSV等。使用makesense.ai进行数据标注可以提高工作效率,同时也可以保证数据的安全和保密性。该工具的界面简洁明了,操作简单,非常容易上手。
三、在自有数据集上训练
1. 配置文件修改
依据官方教程所给出的方法,可在已有的yaml配置文件上进行修改,从而可以训练自己的数据集。官方教程(链接:https://docs.ultralytics.com/yolov5/tutorials/train_custom_data/ )中以coco128.yaml的配置文件为例进行了说明,我们在实际使用时,只需要将其修改为mask.yaml即可。
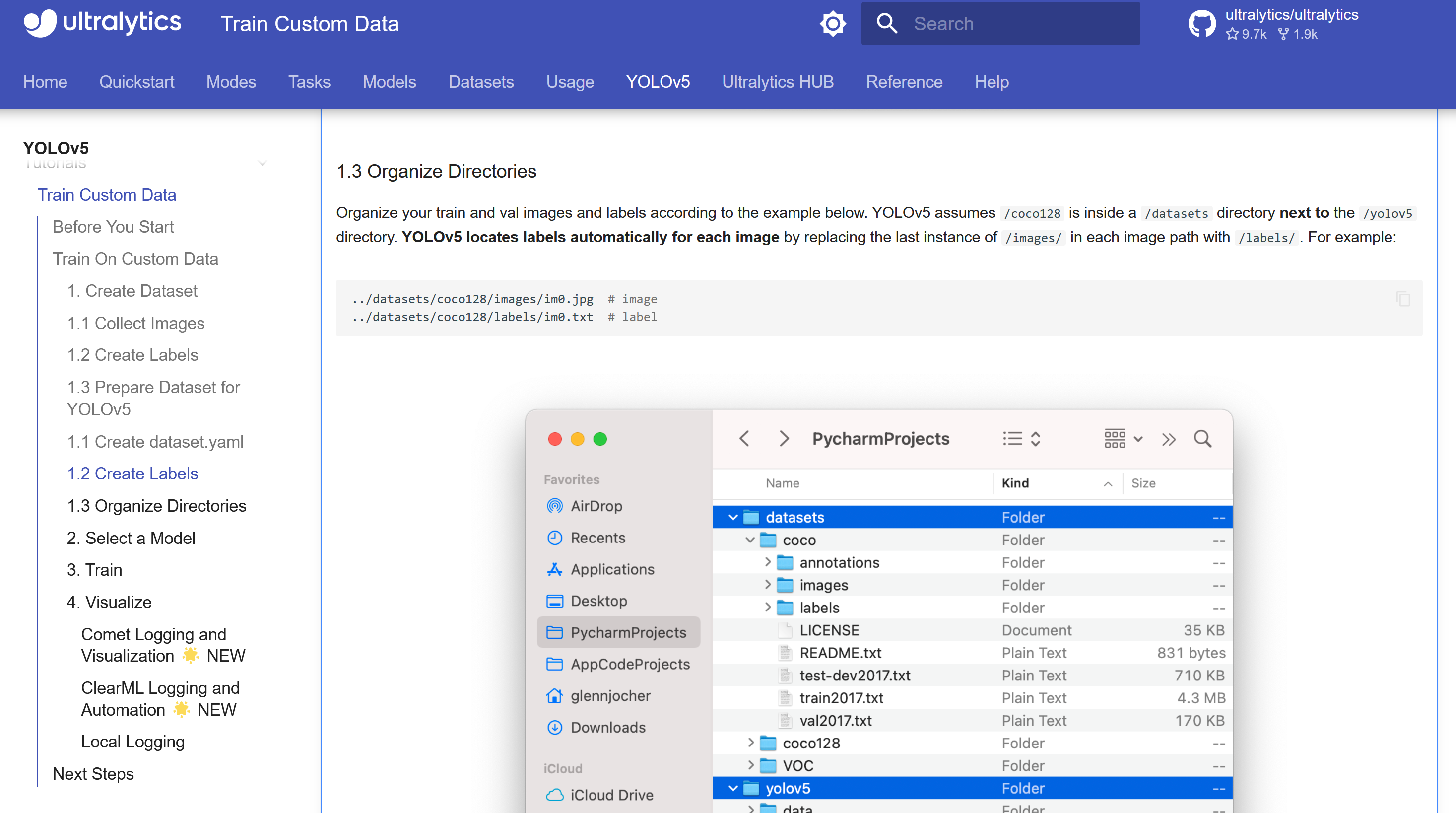
在文件路径配置上,yolov5的训练,会读取和yolov5-master平行的文件夹dataset里面的内容。

在dataset文件夹当中新建mask文件夹,mask文件夹内新建images和labels两个文件夹。将图片拷入images文件夹,而将makesense.ai网站当中生成的压缩包解压之后放置在labels文件夹中。
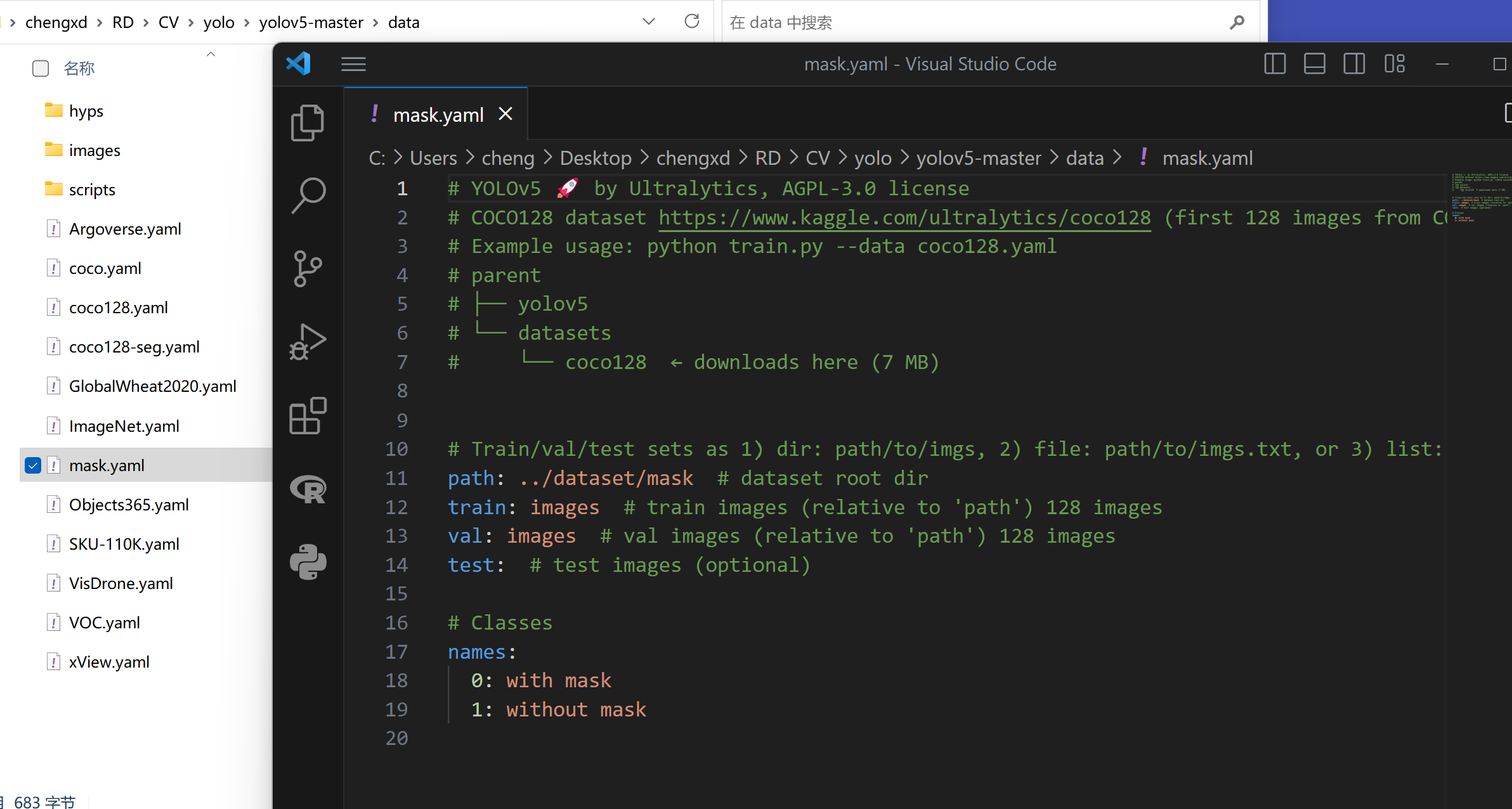
随后,在yolov5-master下的data文件夹当中找到coco128.yaml,复制该文件并改名mask.yaml。针对自己的数据集进行修改。其中将paths处修改为 ../dataset/mask,也即定位自有数据集的相对路径。修改标签,仅保留0为with mask,1为without mask。修改后的mask.yaml配置文件如下图。
删除原有的coco128.yaml当中的download指令。
删去此行:download: https://ultralytics.com/assets/coco128.zip
通过直接修改yaml配置文件,可以避免在train.py文件当中频繁修改所带来的诸多报错问题。 CSDN上不少教程要求用户自行修改train.py,是一项极不负责任的行为,说明这些教程的作者没有阅读官方的说明文档,也没有理解通过yaml专用配置文件直接传入这种更为简洁优雅的方法。
2. 训练模型
依据官方教程所给出的方法,可以通过命令行传入不同的参数,来实现对于train.py当中调用实际指令的修改。
如下指令,img 640也即图像大小为640传入。Epochs为迭代和训练次数,本次选择100轮训练。Data即为选择配置文件,此处为前文所配置好的mask.yaml。Weights为预训练模型,此处以yolov5s.pt预训练模型的基础之上进行训练。
python train.py –img 640 –epochs 100 –data mask.yaml –weights yolov5s.pt
在命令行中输入以下指令后,敲击回车即开始训练。由于有100轮训练,所需时间较长,建议在这个时间去喝个咖啡,等待训练完成。 一般而言,训练迭代次数要依据你的模型复杂程度来确定,但无论多么简单的模型,50轮的训练都是少不了的。这也是AI模型消耗算力的根本原因——需要通过无数的迭代才能够达到预想的效果。
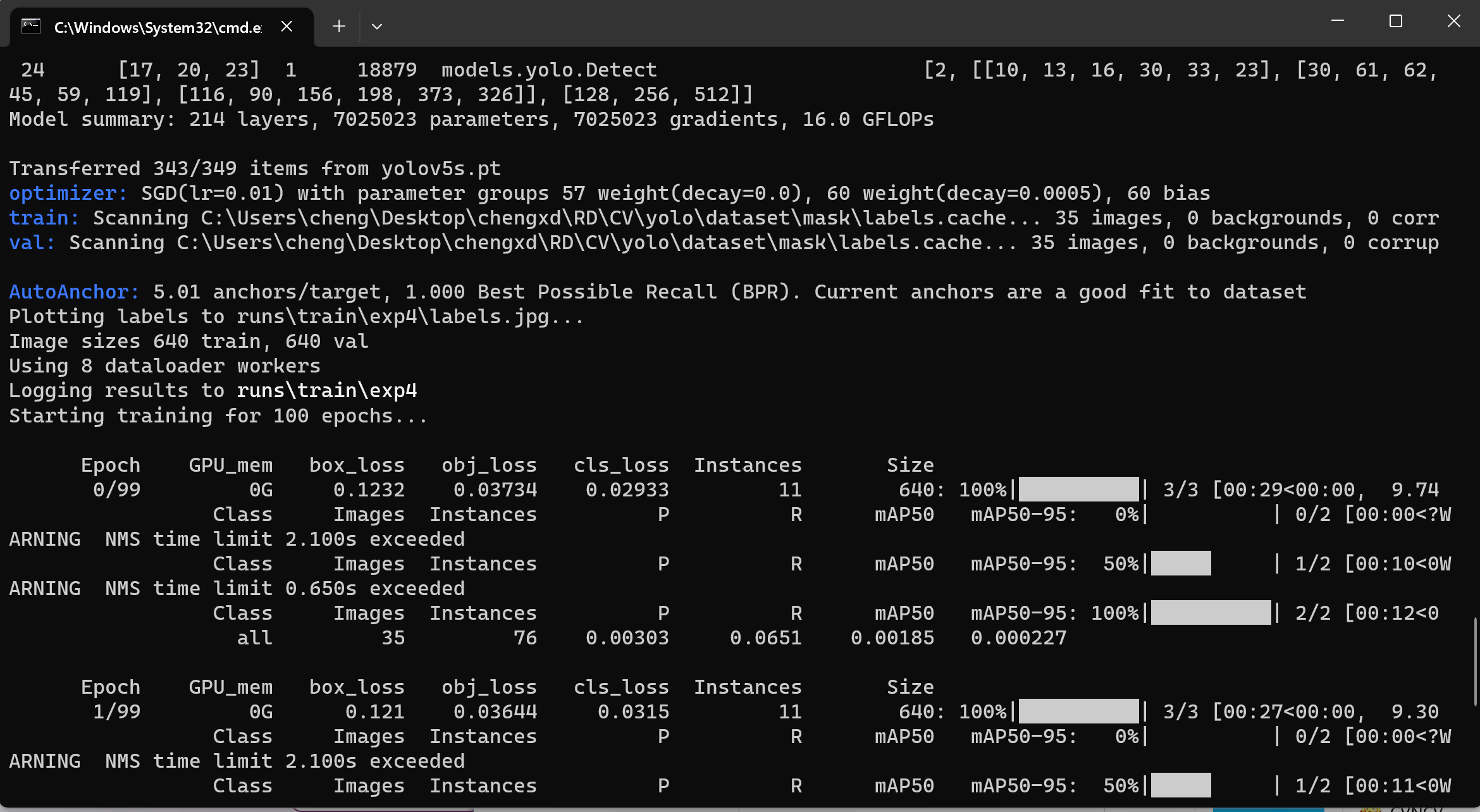
训练完成后,在run文件夹下的train文件夹中,找到你进行的那一次训练
在weights文件夹当中找到best.pt这个权重文件,也即是你训练出的模型当中效果最好的那个权重文件。
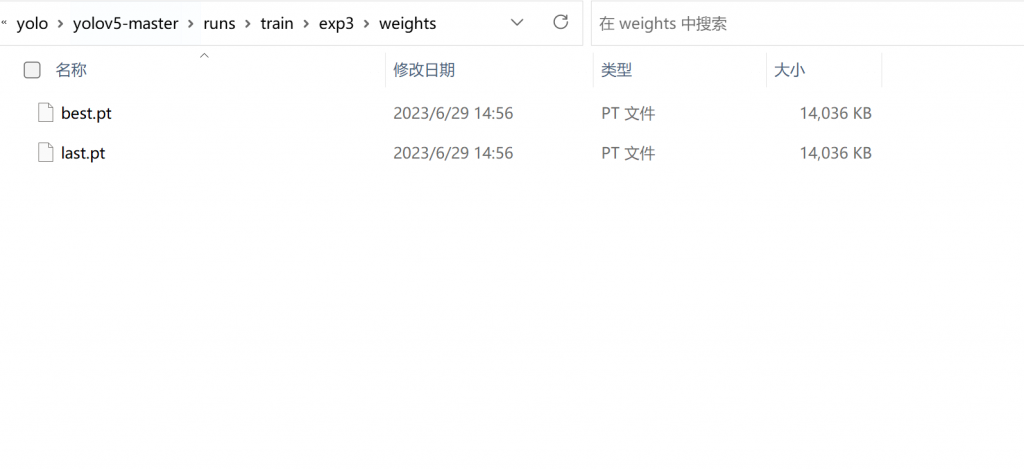
复制该best.pt到yolov5-master文件夹下,随后运行并调用该权重文件即可。
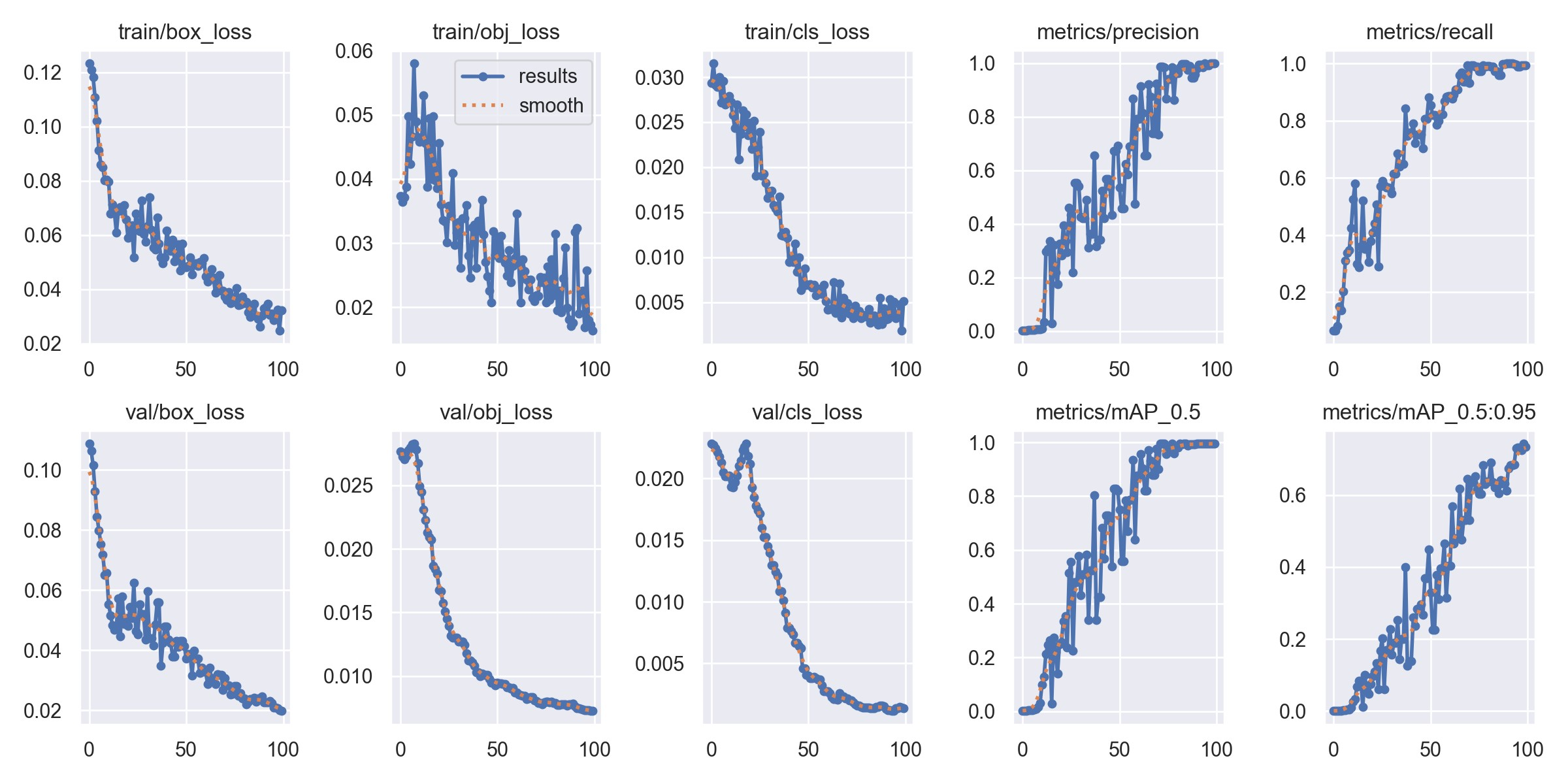
3. 训练结果
本次训练相关结果如下:损失函数、查准率、查全率等、平均精度等相关训练参数曲线。
相关数据集验证如下,基本准确识别。

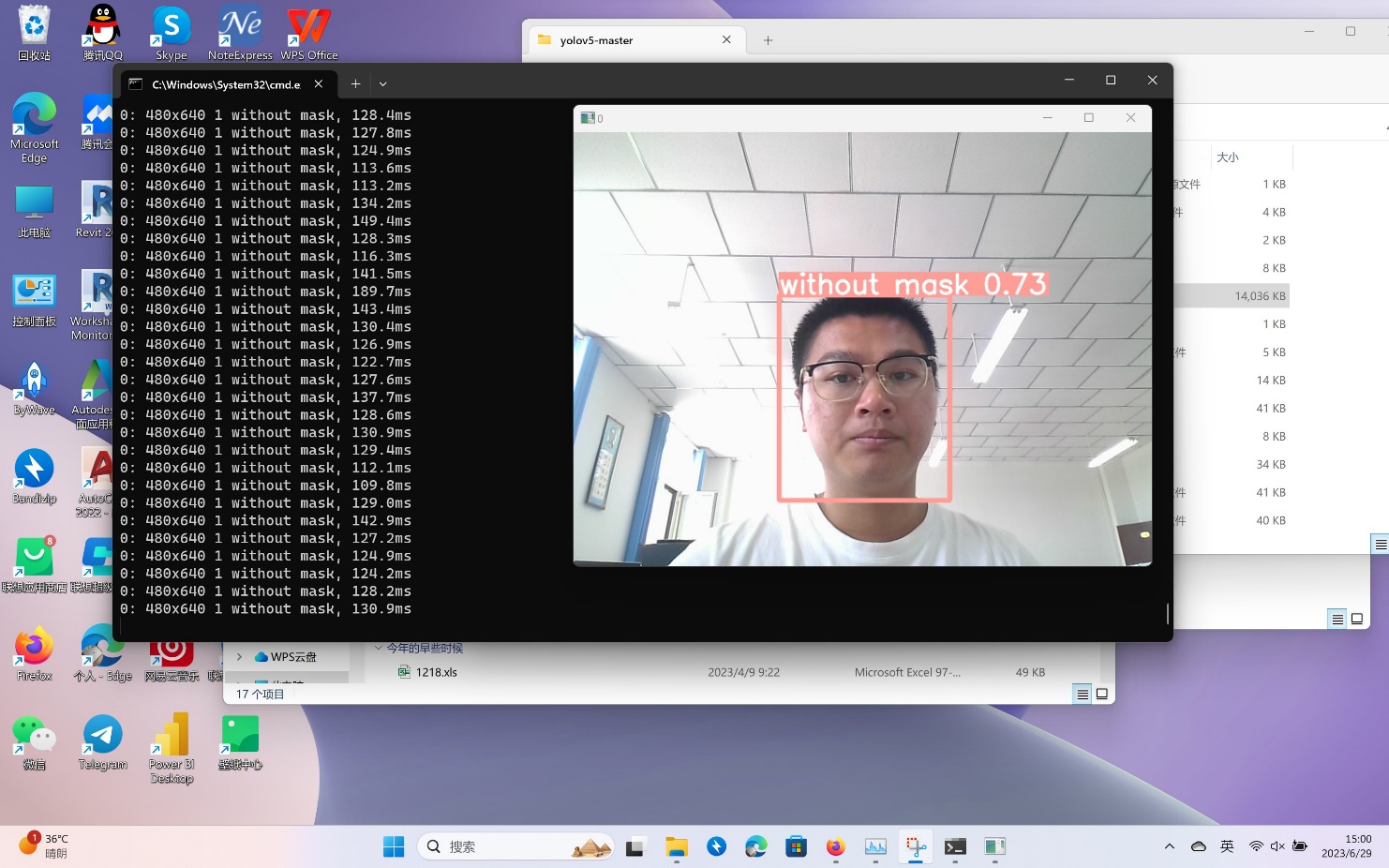
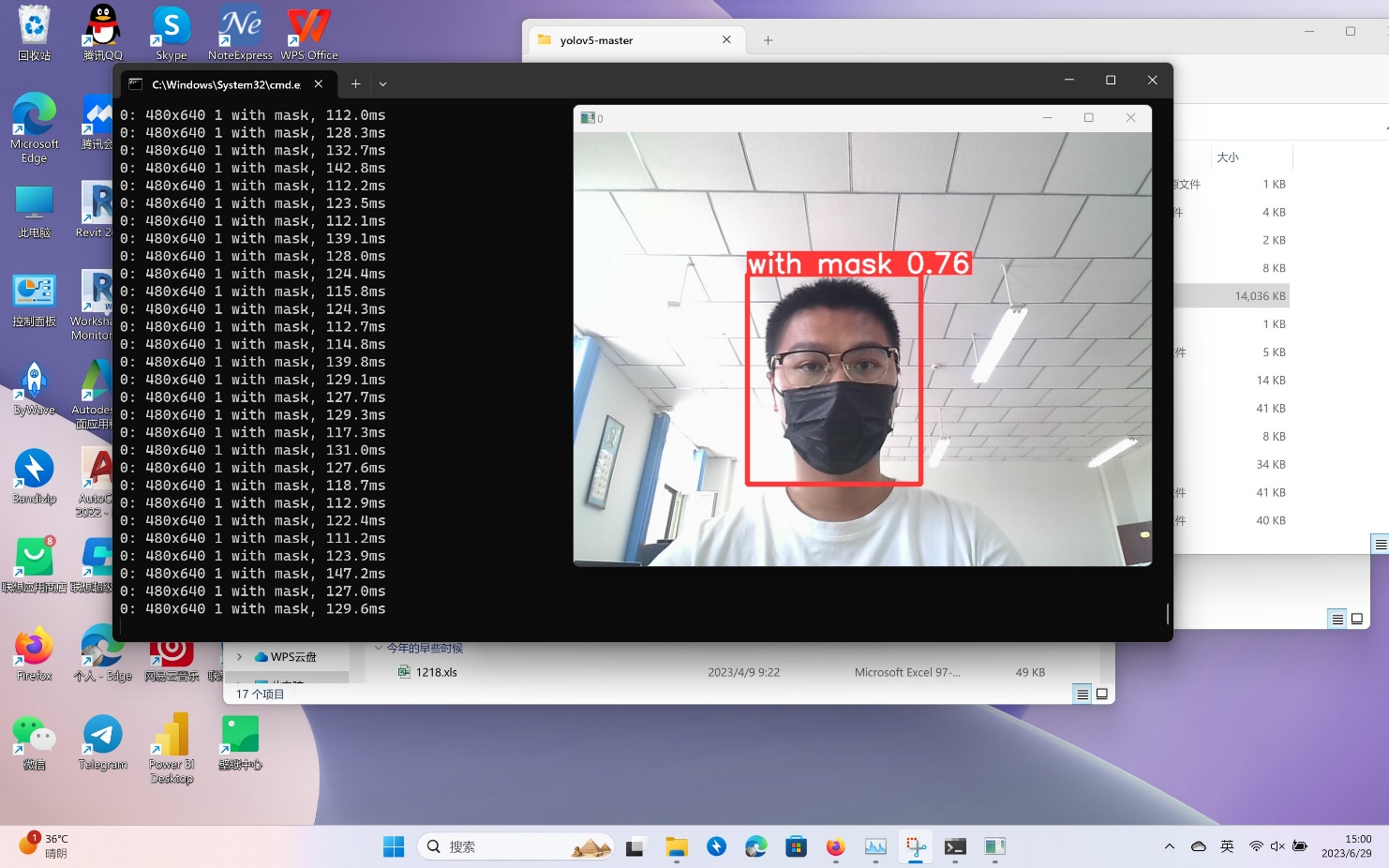
最后,调用摄像头对于本人训练模型进行验证,能够准确识别是否佩戴口罩。
启动调用摄像头的cmd命令行activate yolov5之后,输入命令python detect.py –weights best.pt –source 0
其中weights为调用此前训练好的权重文件,而source 0则是调用本机摄像头进行。
![]()