
2025年10月9日,英特尔正式发布的 Panther Lake 酷睿 Ultra 300 系列,标志着其在移动端处理器架构上的又一次重大更新。
笔记本电脑评测网联合著名数码博主金猪升级包,对于英特尔酷睿Ultra 300系列产品线做独家解析。
产品线总体定位
与 2024 年的 Arrow Lake 与 Lunar Lake 系列不同,Panther Lake 是 酷睿 Ultra 300 系列中唯一的代号。这一代产品仅面向 笔记本电脑移动端平台——既没有桌面端版本,也没有高性能的 HX 型号。

当前的Arrow Lake 酷睿Ultra 200HX,会在2026年进行一次Refresh,可能会叫做酷睿Ultra 200HX Plus,但不会叫做酷睿Ultra 300HX。后续下一代产品Nova Lake HX,可能会直接叫做酷睿Ultra 400HX。换而言之酷睿Ultra 300HX这一命名被跳过了。
英特尔官方的定位,是让 Panther Lake 全面取代 Arrow Lake-U/H 及 Lunar Lake-V 的位置。然而,从市场策略和实际性能来看,这种“完全替代”仍存在分层:
- Panther Lake 在定位上更高,价格相对昂贵;
- 它并不能在极低功耗设备上完全替代 Lunar Lake-V,因为后者更注重能效与超轻薄设备应用。

架构演变:从四 Tile 到三 Tile
Panther Lake 延续了自 Meteor Lake 以来的多芯片模块化设计,但在架构上做出了简化与整合。
Meteor Lake和Arrow Lake 架构类似,四 Tile 架构如下图所示——
- CPU Tile:主要计算核心
- GPU Tile:核心显卡
- SoC Tile:集成 NPU、Media Engine 等通用组件
- IO Tile:负责 I/O 接口扩展
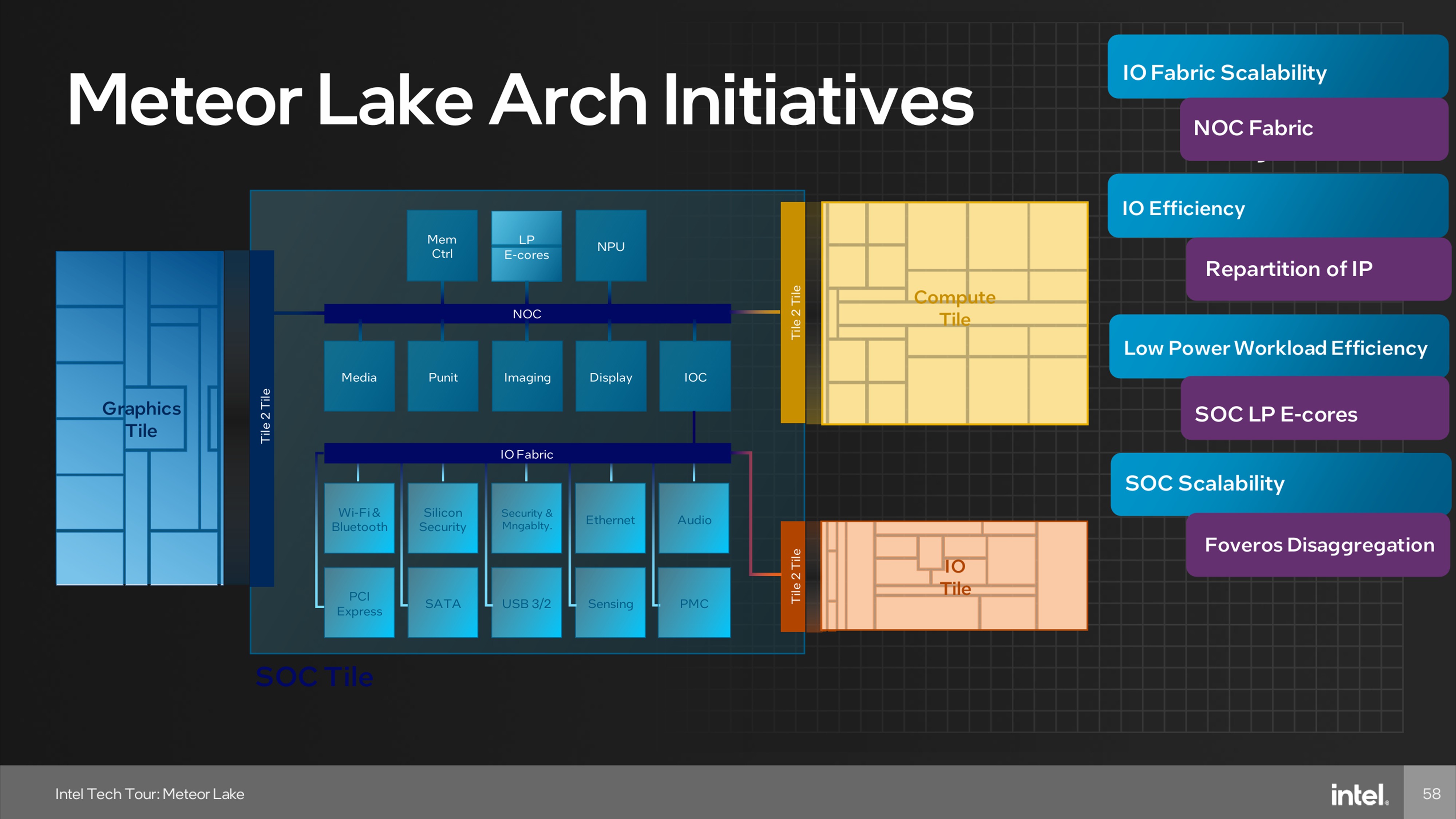
这种设计首次实现了模块化封装,但 SoC Tile 的功能相对复杂,既涉及部分计算单元又管理 I/O,造成内部划分不够清晰。
Panther Lake 的三 Tile 架构
Panther Lake 对这一结构进行了优化:
- Compute Tile:整合了 CPU、NPU、Media Engine 等主要计算与加速单元;
- GPU Tile:独立存在,便于扩展不同等级的核显;
- Platform Control Tile(PCT):负责 I/O、Thunderbolt、USB、PCIe 等平台控制。

这种简化后的三 Tile 结构使芯片层次更加清晰,规划更利于不同 SKU(芯片型号)的共用封装设计。
英特尔特别强调,Panther Lake 各型号在物理封装上 实现了统一(Same Package Across All Designs)。

这意味着:
- 不论是 8 核标准版、16 核性能版,还是 16 核大核显版,都可以在同一主板上互换使用;
- 整机厂商(OEM)可在同一模具上验证不同配置,从而大幅降低开发与验证成本。
这“Pin-to-Pin 兼容”,提升了整个平台的灵活度。不过,实际在电气设计与功耗控制上仍有细节限制,完全的互换性还需视具体机型而定。
三大细分型号与应用场景
Panther Lake 系列延续了从能效到性能的分层布局,共分为三种核心配置:
- 入门款:8核 + 小核显
- 主打轻薄笔电,极低功耗;
- 成本较低,部分型号作为 Lunar Lake-V 的派生替代方案。
- 中端款:16核 + 小核显
- 面向游戏本或高性能轻薄本;
- 搭配独显使用,因此 PCIe 通道分配更灵活。
- 高端款:16核 + 大核显
- 集成高性能核显(大核显版 GPU Tile);
- 适用于不依赖独显的高端轻薄产品。

这种结构既覆盖超低功耗产品,也满足对 GPU 性能和可扩展性的需求。
值得注意的是,Panther Lake 系列在 CPU 描述与宣传方式上,也出现了明显的转变。英特尔不再像以往那样着重区分 P-core(性能核) 与 E-core(能效核) 的数量,而是采用更简洁的总核数标识。例如,“8 核处理器”不再说明是“4 大 + 4 小”或“6 大 + 2 小”,而是统一称为“8 核”。
这种做法显然是 向 AMD 的命名策略靠拢。AMD 早先便以“总核数”命名,例如其 8 核 CPU 可能是 4+4 混合设计,而市场与用户通常不去细究内部结构。英特尔此举在营销层面上更容易让消费者理解,也避免了“几大几小”的专业术语带来的认知负担。
8核+4Xe的小核小显版本(PTL 404)
首先来看8核+4Xe的“小核小显”版本,也就是PTL 404版本。
在具体配置上,Panther Lake 的这一型号与 Lunar Lake 的设计理念十分接近,采用 4 个高性能核心(P-core) 搭配 4 个低功耗核心(LP E-core) 的组合。这里的 LP E-core 属于低功耗岛(Low Power Island),并不与性能核心共享同一 Ring Bus。从结构上来看,这种设计能够让 LP E-core 在轻负载任务下独立运行,从而有效降低整机功耗。
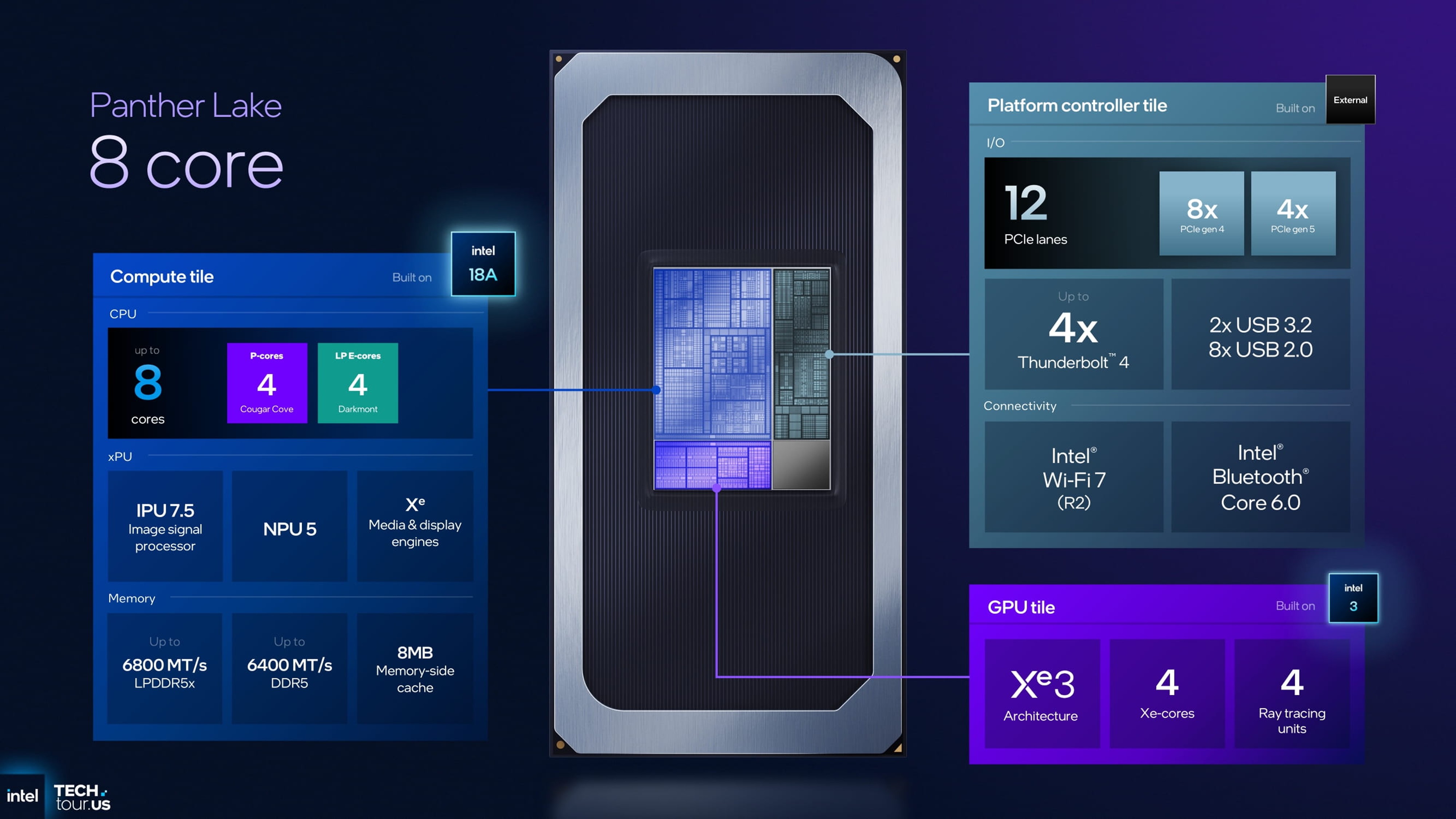
在内存支持方面,该版本最多支持 LPDDR5X 6800 MT/s 与 DDR5 6400 MT/s,并保留了 8MB Memory Side Cache(内存侧缓存)。该缓存机制源自 Lunar Lake,可在带宽受限的情况下减少内存压力,提高数据访问效率。整体而言,Panther Lake 在 CPU 架构上与 Lunar Lake 十分相似,尤其是在能效与缓存设计思路上延续了前代的经验。
图形子系统则升级至 Xe3 架构,这是英特尔新一代集成 GPU 技术。不过,该版本仅配备 4 Xe 图形单元,只是 Lunar Lake 的一半规模。该型号在图形性能上更接近 Arrow Lake-U 的直接继任者,而非对 Lunar Lake 的完整替代。
在制造工艺上,不同模块采用了混合制程:
- CPU Tile 使用 Intel 18A 工艺;
- GPU Tile 采用 Intel 3 工艺;
- Platform Control Tile(PCT) 则基于 台积电 N6 工艺。
这种多节点封装延续了英特尔的模块化策略,在性能、成本与能效之间寻求平衡。
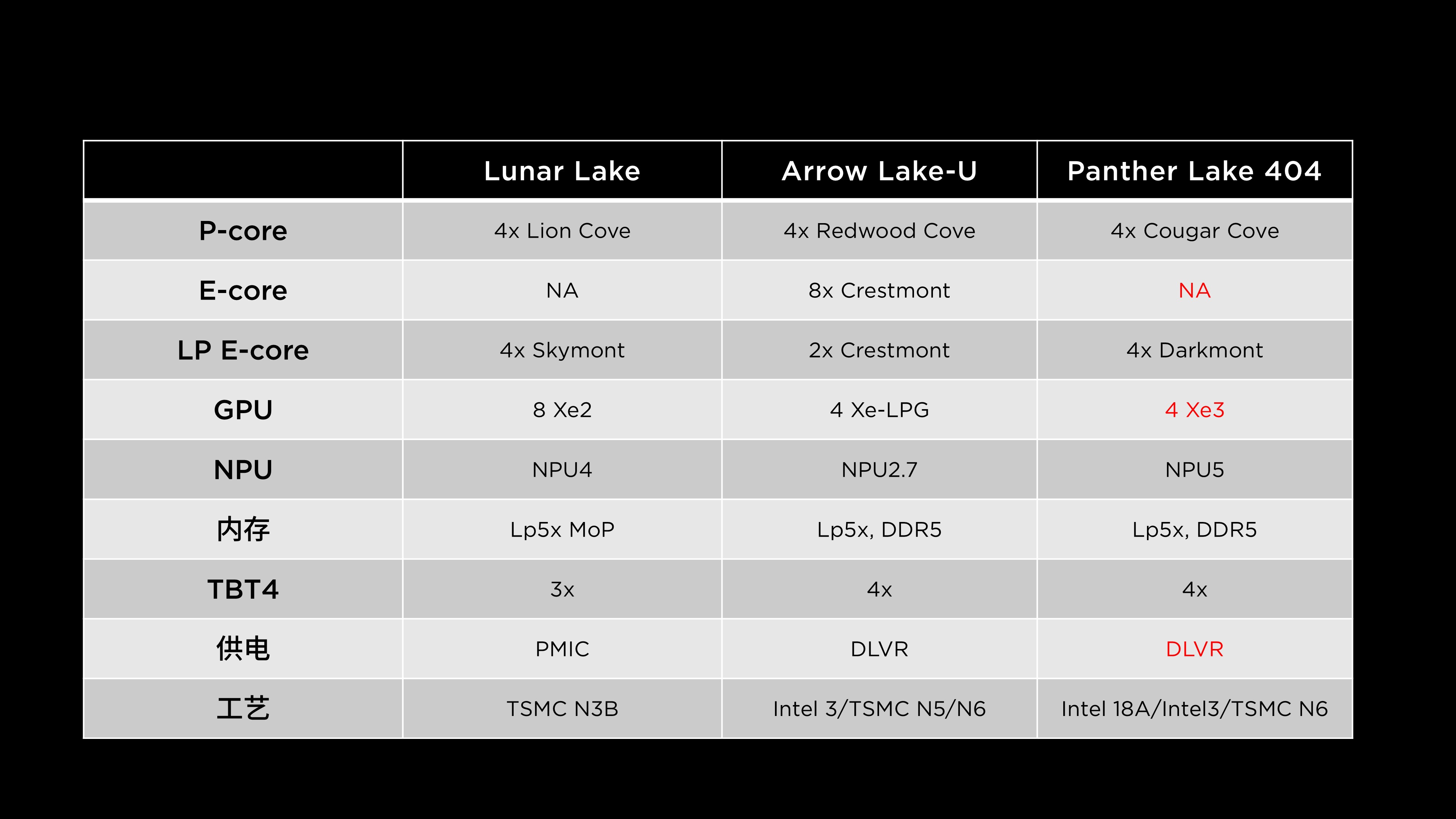
Panther Lake PTL404 相较于 Arrow Lake-U 取消了传统的 E-core 设计,而与 Lunar Lake 相比,则在核显规模上略有缩减。内存支持LPDDR 5x核DDR 5,不支持 MOP(封装内存)方案,这在功耗影响上并不显著,但会让整机主板布局更为灵活。
PTL 404 的 Thunderbolt 支持 与 Arrow Lake-U 保持一致,供电架构方面同样延续了后者的 DLVR 动态调压设计。整体来看,这一版本凭借轻量化 GPU 和均衡的 CPU 架构,主要面向主流轻薄型笔记本市场,兼顾能耗与性能需求。
在供电方案上,PTL404 继续采用 传统的 DLVR(Digital Linear Voltage Regulator)稳压架构,而非 Lunar Lake 所使用的 集成式 PMIC(电源管理芯片) 方案。英特尔选择延续 DLVR 的设计,主要出于 成本控制与平台兼容性的考虑。
PTL404 的市场定位是 Lunar Lake 办公型笔记本的直接继任者,定位于轻薄型办公与高能效使用场景。
16核+4Xe 大核小显版本(PTL 484+4Xe)
继 8 核小核显型号之后,Panther Lake 系列还包含一个 大核小显版本,这个版本主要是为游戏本准备的。
该版本在配置上新增了 8 个能效核心(E-core),形成了 4 个性能核心(P-core) + 8 个能效核心(E-core) + 4 Xe 单元核显 的 “484” 架构。这一组合方案早已被业内确认,有些人幻想中英特尔会推出六大核版本,但最终并未出现,4+8+4 的配置也成为定案。
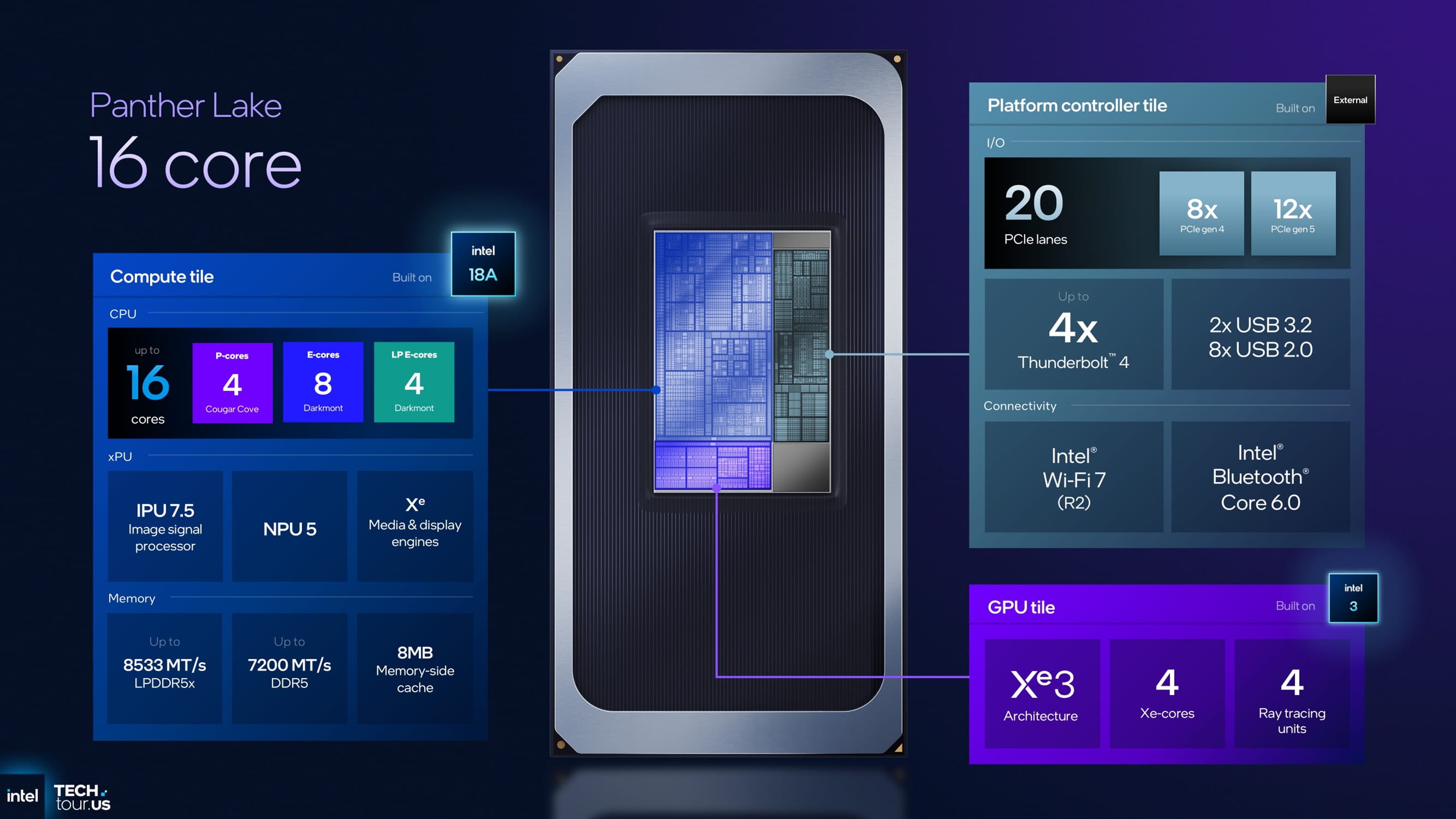
PTL 484+4Xe 在内存支持上进一步提升,最高可支持 DDR5 7200 MT/s 的原生 JEDEC 标准频率,这是目前业界笔电平台中所支持的最高原生频率。为了实现这样的性能,该版本采用 CSODIMM(Compact SO-DIMM) 设计,并通过集成 CKD Redriver 实现高频下的时序补偿和信号稳定,从而实现 7200 MT/s 的稳定原生支持。8MB的Memory Side Cache也同样予以保留。
为了适配独立显卡配置,平台控制模块(PCD)新增了 8 条 PCIe 5.0 通道,使系统总共具备 20 条 PCIe 通道。集成显卡部分延续了 4 Xe 单元的 Xe3 架构 GPU,与 8 核版本保持一致。
与上一代 Arrow Lake 平台相比,这一型号的主要变化集中在核心数量的变化与接口规格的调整。其 CPU 大核数量是4个,与上代的 Ultra 5 级型号基本相同,相比于Ultra 7的6个大核少了2个。英特尔新的口径是“小核才是真大核”。
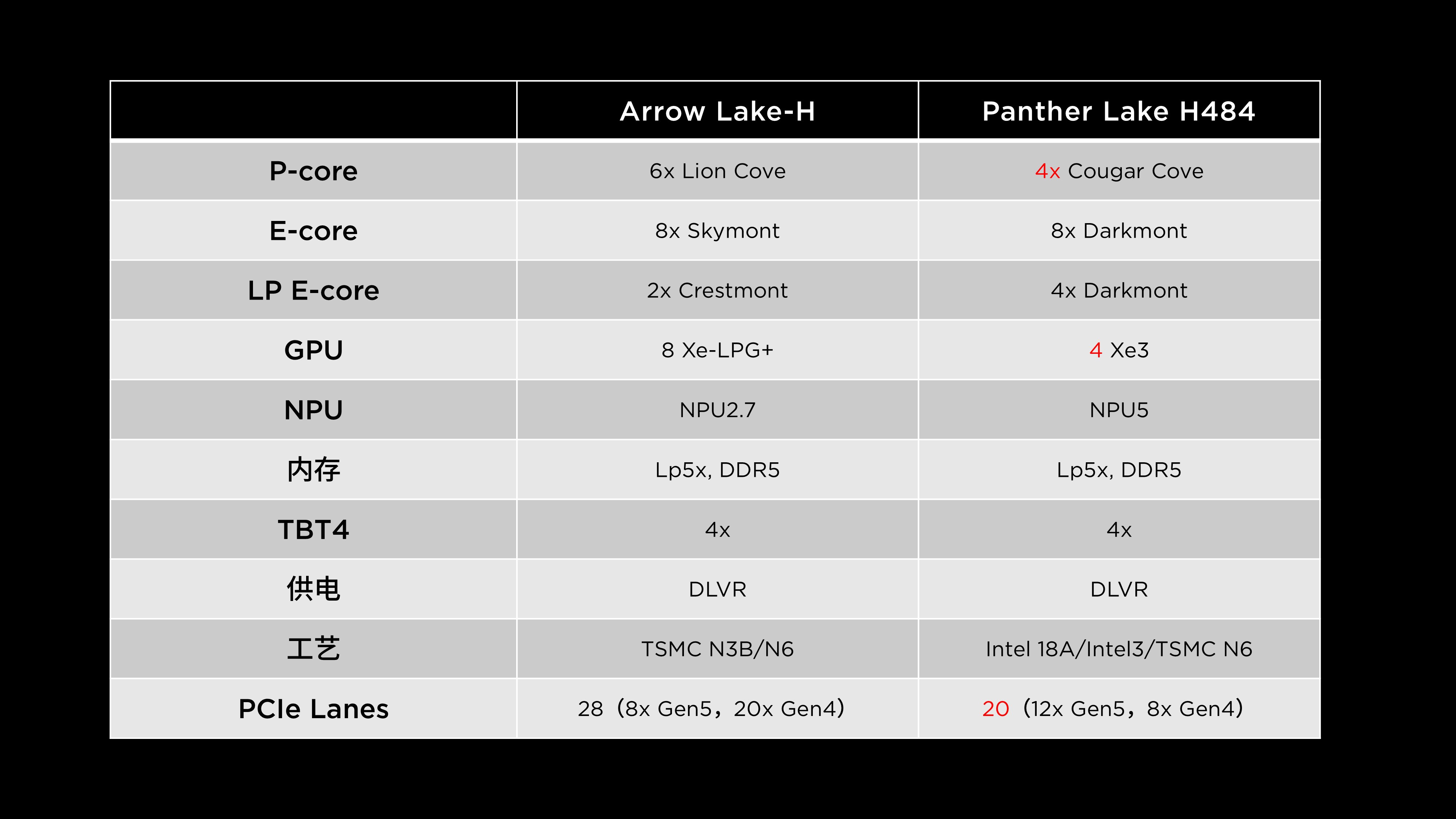
核显保持 4 Xe 配置主要出于成本因素的考量。相比高配的 Arrow Lake-H 系列,PTL 484+4Xe的大核小显版本预计会搭载高功耗独显,因此保留小规模核显即可满足主流图形输出需求。
在 AI 运算方面,NPU(神经网络处理单元) 从上一代的 NPU 2.7 升级为 NPU 5,支持新的 Copilot+ PC(AIPC) 功能,可运行包括 “Recall” 等在内的多种 AI 助理特性。
内存、供电及接口体系方面,大核小显版本与前代 Arrow Lake 保持了较高的一致性。CPU 依旧采用 Intel 18A 工艺,核显部分为 Intel 3 工艺。尽管整体性能有所增强,但在 PCIe 通道数量上,英特尔对其进行了精简——由上代的 28 条缩减至 20 条,主要减少了部分 Gen4 通道配置。
这一调整的原因在于,此前的 Arrow Lake-H 在 PCIe 通道分配上相当“奢华”,28条PCIe实际上远超轻薄本的需求。如今的 20 条配置更加合理,毕竟AMD也是20条。
在具体分配上,通常厂商会这么做:
- 8 条用于独立显卡;
- 8 条分给两组存储设备;
- 剩下的 4 条为通用高速端口(GPP),用来连接网卡或读卡器等外围设备。
这种设计既满足性能笔电的扩展性,又控制了功耗与主板复杂度,当然最核心还是为了控制成本,成为 Panther Lake 平台在中高端轻薄机型中的标准配置。
16核+12Xe 大核大显版本(PTL 484+12Xe)
在 Panther Lake 全系产品中,“大核大显”版本位于性能最高的一档。
该型号的 CPU 部分与前述的大核小显版本在核心配置上完全一致,同样采用 4 个性能核心(P-core)与 8 个能效核心(E-core)的 12 核架构。主要区别来自于图形与内存系统——由于搭载了规模更大的集成显卡,其在内存规格和工艺设计上进行了相应的调整。

PTL 484+12Xe 仅支持 LPDDR5X 内存,不再兼容 DDR5。这一设计是出于带宽需求的考虑,更高性能的核显需要更快的内存子系统。LPDDR5X 的最高支持频率提升至 9600 MT/s,成为目前行业中集成 GPU 平台所支持的最高原生速度。
PTL 484+12Xe GPU Tile 的制造方面,Intel 3 工艺已无法满足这种大规模 GPU 的晶体管密度。因此,英特尔选择交由台积电制造,采用 TSMC N3E 工艺节点。与Lunar Lake采用的 N3B 相比,N3E 工艺更为成熟、成本更低。高通骁龙8 Elite同样采用了N3E来降本增效。英特尔此举的目的在于 降低制造成本、提高模块的可扩展性与复用率。
不过,即便进行了“成本优化”,由于 GPU Tile 尺寸大幅增加,整体生产成本依旧相当高。所谓的“Cost Down”更多是指在高成本前提下,通过模块复用来控制开支,使产品仍具商业可行性,而非真正意义上的廉价方案。
PTL 484+12Xe 依旧保持 12 条 PCIe 通道,具体设计与 8 核版本(PTL404)一致,并未针对独显使用做扩展。由此可见,大核大显版本同样以核显为主要图形输出核心,并不考虑外接独立显卡的设计需求。
与 Arrow Lake 平台相比,大核大显版本的特点非常明显:
- 性能核心数量略少,但 集成显卡性能显著增强;
- NPU(神经网络处理单元) 升级为 NPU 5,AI 处理能力更强;
- 仅支持 LPDDR5X 内存,取消 DDR5 兼容;
- 供电架构依然沿用 DLVR 稳压方式;
- PCIe 通道数量 缩减为 12 条,这限制了部分高带宽扩展方案。
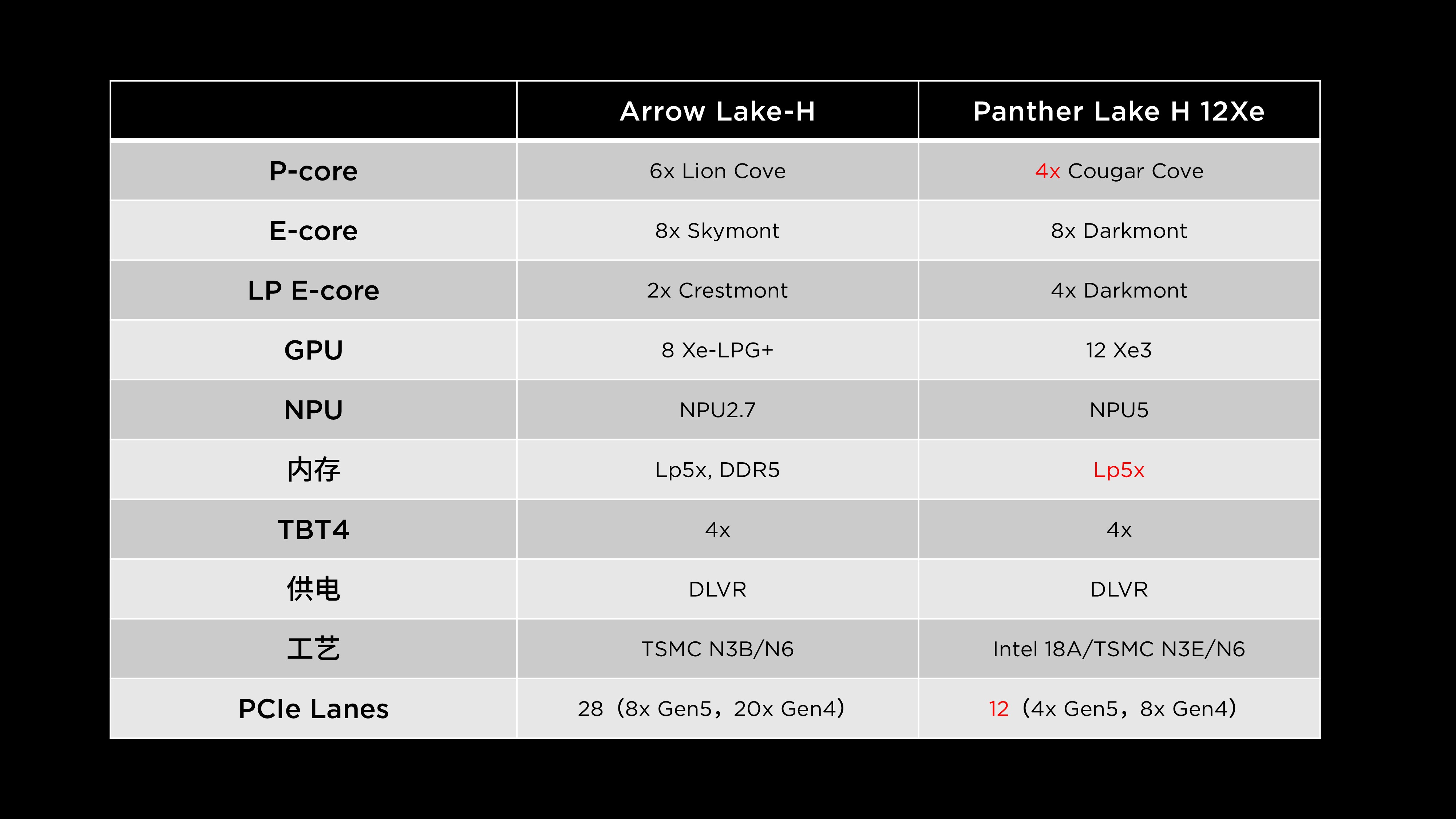
从应用角度来看,在这种通道配置下,如果笔记本主板预留两个 M.2 NVMe 插槽(共占用 8 条 PCIe 通道),系统仅剩 4 条可供其他外设分配。这样一来,若要额外配置如 Oculink 外接 GPU 接口,就可能面临通道分配不足的问题。设计者需要在以下设备间做取舍:
- 有线网卡(RJ45 接口)
- 无线网卡(CNVi 接口)
- 读卡器等外围模块
比如会取消 RJ45 有线网口,通过 CNVi 无线方案提供网络连接,读卡器转接至 USB 总线,就能在有限的通道预算下维持平台完整性。
总体上,大核大显版本强调的是 高集成度与强图形计算能力,在不采用独显的前提下,为高端轻薄本提供接近中端独显水准的图形与 AI 性能表现。这一设计使得 Panther Lake 系列在轻薄本、高能效本以及 AI 计算本市场形成完整的规格层次。
产品线梳理
至此,我们就完整看完了整个 Panther Lake 家族 的产品布局。可以看到,英特尔在这代产品中如同之前所强调的那样,不再对外宣传具体的核心类型和分配方式,而是以总核数作为唯一标识。例如,PTL404 就直接称为“8 核”,484 型号称为“16 核”,至于其中性能核与能效核的具体比例,则不再单独说明。

CPU 性能
从现有资料来看,Panther Lake 的 CPU 性能提升相对有限,并没有出现预期中显著的跃升。英特尔主要在能效方面进行了强化,而性能增幅并不突出。
官方给出的数据中,Panther Lake 的单核性能基准比较对象并非 Arrow Lake,而是 Lunar Lake。相较于 Lunar Lake,它在 CPU 单核性能上大约提升 10% 左右。图中Panther Lake对比的产品分别是酷睿Ultra 9 285H核酷睿Ultra 9 288V。
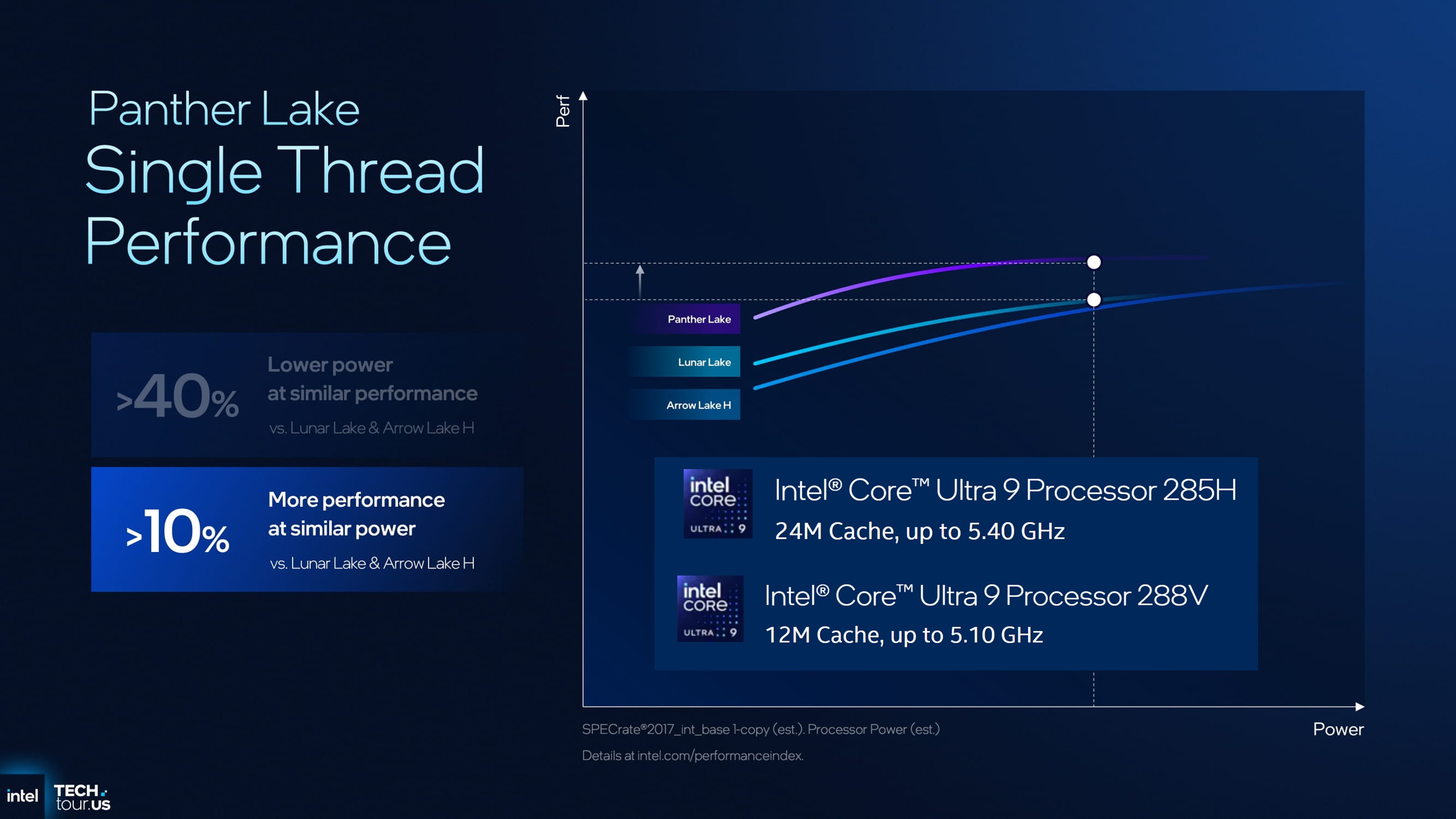
根据性能曲线图可以看到,Lunar Lake 的性能增长趋势已接近阶段峰值,Arrow Lake 仍有一定上升空间,而 Panther Lake 在整体性能曲线中则趋于平稳。由于 Lunar Lake 与 Arrow Lake 高端型号之间,本身频率差距就可带来约 6% 的性能差异,因此推算下来,Panther Lake 的单核性能相对 Arrow Lake H 仅提升约 5%~6% 左右,属于个位数级别的改进。
值得注意的是,本代中 LP(低功耗)小核心已能参与前台计算任务,因此在多线程性能的释放上比前代更积极。
多核性能曲线上表现良好,但仍未敢直接与 Arrow Lake 正面对比。英特尔标明的提升主要针对同功耗条件下的 Lunar Lake:多核性能提升约 50%。这一部分的优势主要来自于核心数量的增加与工艺升级的加成。
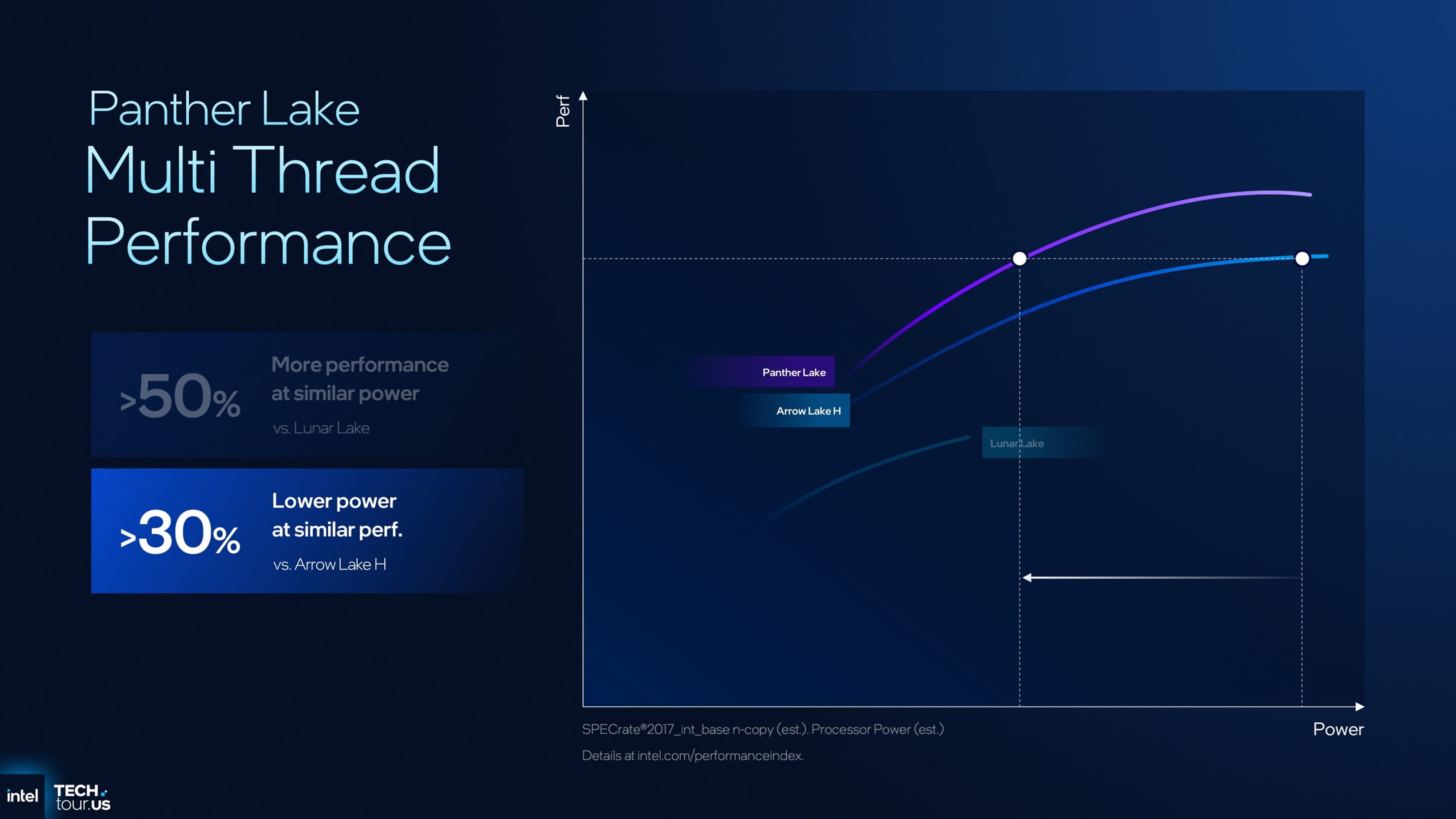
当将其与 Arrow Lake 比较时,英特尔指出 在相同性能水平下,功耗降低约 30%。整体而言,Panther Lake 的 CPU,在单核与多核方面都不应期望过高,其优势主要体现在 能效优化 而非绝对性能。
核显性能
与 CPU 相对温和的进步不同,核显性能 是 Panther Lake 的最大亮点。英特尔对其12Xe规格的Xe 3架构核显展示出了极大的信心,从内部图表到对比数据,都显示出显著提升。
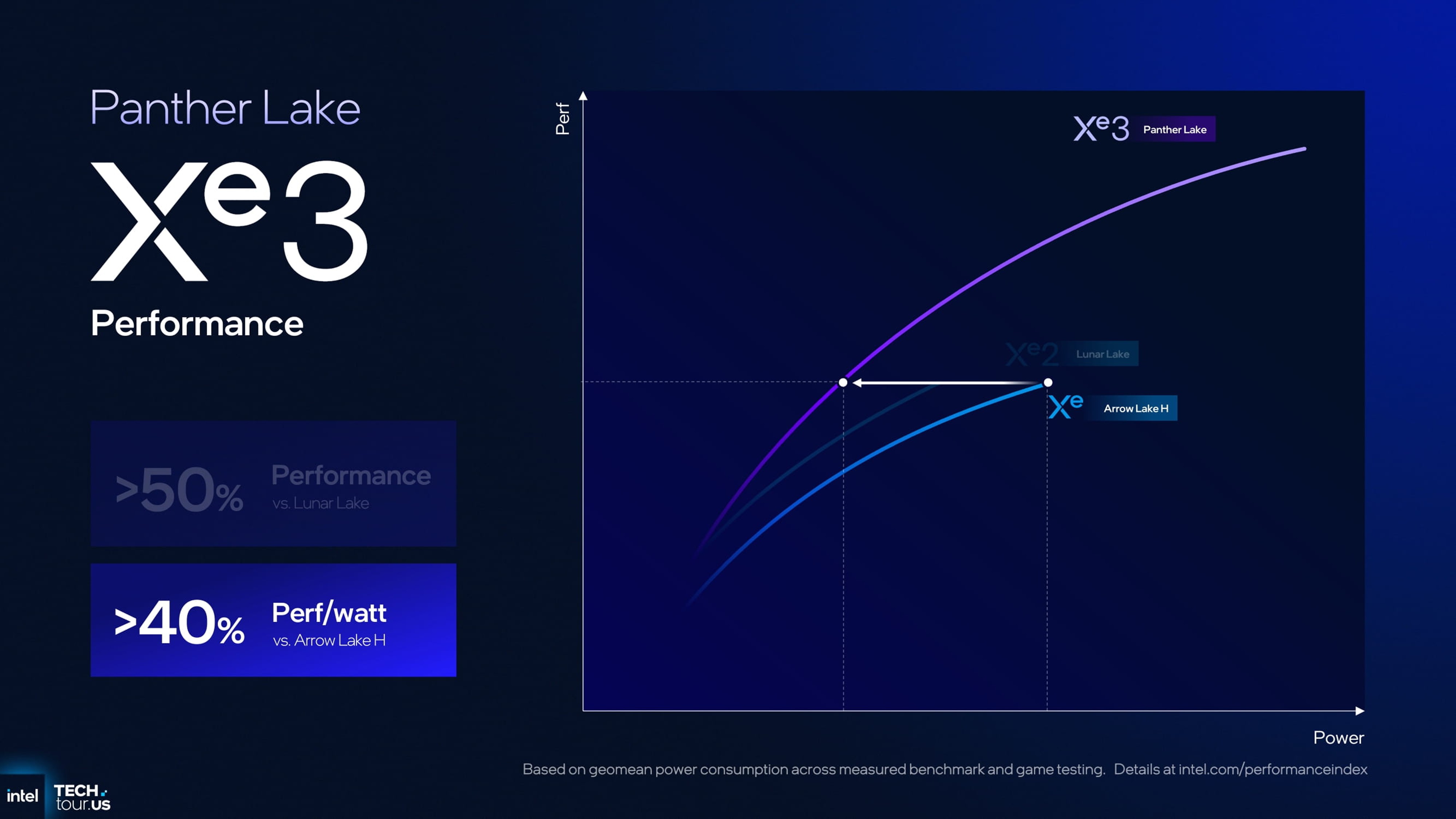
本代配备的 12 Xe(Xe3 架构)核显 相比 Lunar Lake 的核显,性能提升超过 50%。这一数值是在不考虑功耗时的纯性能对比下给出的。若按照当前业界常用的 3DMark Time Spy 测试成绩推算,Lunar Lake 核显约为 4000 分左右,而 Panther Lake 的 12 Xe 型号理论上可达到 6000 分级别。

以独显性能作类比,6000 分的 Time Spy 成绩 已接近 NVIDIA GeForce RTX 3050 Laptop GPU 水平,甚至逼近 GTX 1660 Ti Max-Q 的区间。若英特尔提供的数据属实,这将使 Panther Lake 的集成显卡成为当下业内性能最强的双通道集显之一。
Panther Lake 的核显还全面支持 Intel XeSS 3.0 超级采样技术,并新增 MFG 帧生成(Frame Generation)功能。这意味着在支持该技术的游戏或应用中,显卡能够利用 AI 插帧算法大幅提高画面刷新率与流畅度。

从理论功能叠加角度来看,其性能潜力可以用一种幽默的方式概括为:
PTL 12Xe + “四倍帧生成” ≈ 优于 RTX 4060 + DLSS 3.5
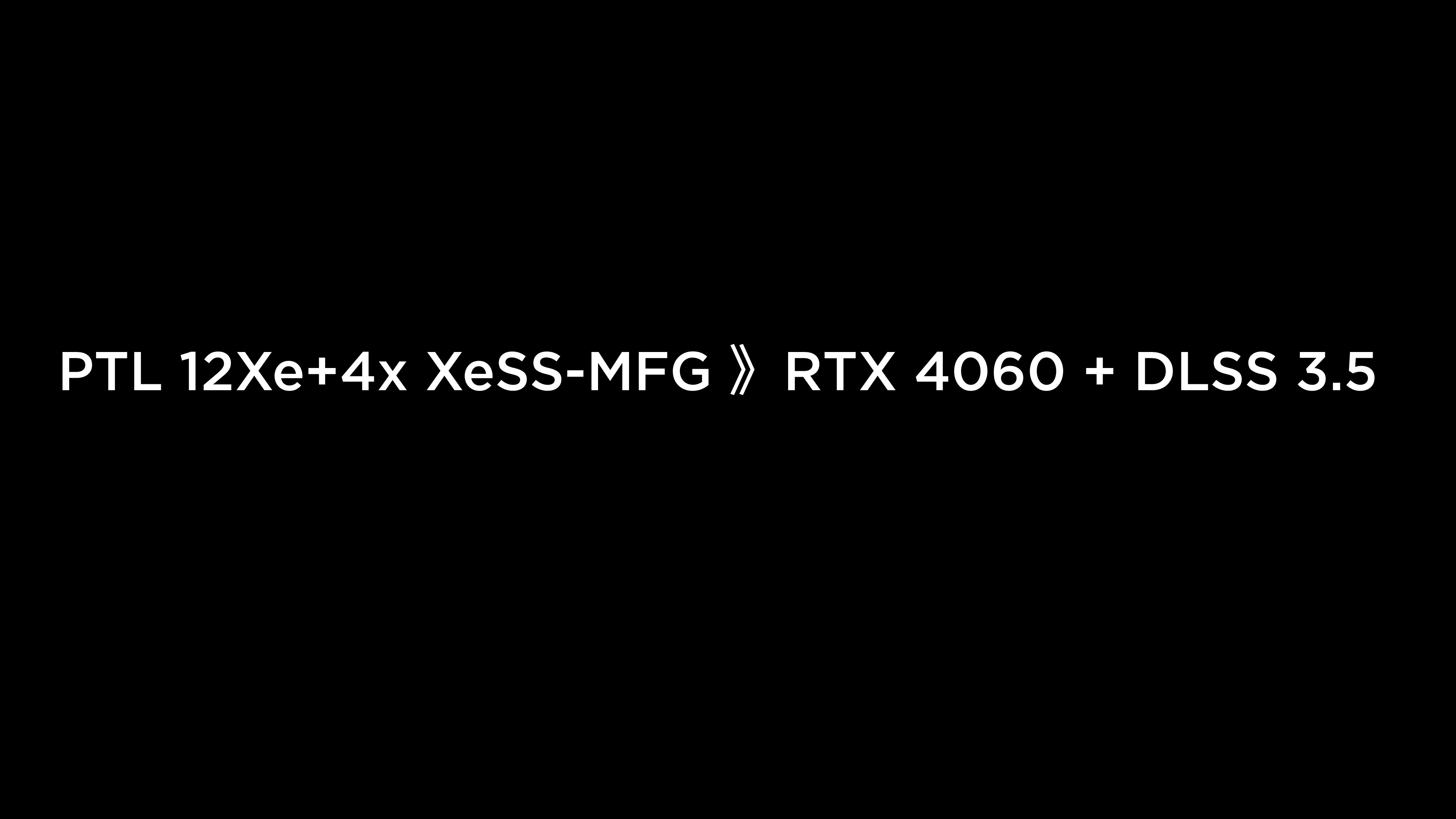
这当然是带有戏谑意味的比较,但却也反映出英特尔对自家 Xe3 核显架构的自信程度。
综合来看,Panther Lake 的 12 Xe 核显 在同功耗环境下具备极高的图形计算能力与 AI 加速潜力。
在接下来的几年内,尤其是在 AMD 平台进入 Refresh 阶段、下一代核显规模下降之前,Panther Lake 的 12 Xe 版本 极有可能长期保持笔电领域最强集显的地位。
正因如此,对于这一代 Panther Lake 的核显表现,用户完全可以放心期待。
Panther Lake 的能耗设计
在分析完性能之后,我们再来看 Panther Lake 的能耗表现。
这一代产品在功耗控制方面大量借鉴了 Lunar Lake(LNL) 的设计理念,尤其在数据访问路径与任务调度策略上延续了相同的思路。
首先,在内存子系统中,Panther Lake 继续引入 Memory Side Cache(内存侧缓存)。该缓存结构主要用于缓解 DRAM 的访问压力,减少内存流量(DRAM Traffic)与带宽占用,从而有效降低能耗与访问延迟。通过减少内存总线频繁访问带来的功率消耗,这一机制对长时间运行的轻负载任务尤为有益。

其次,低功耗岛(Low-Power Island) 设计同样得到保留。这部分由独立的 LP E-core 组成,专门用于处理后台或简单任务。在低功耗场景下,系统会优先将任务分配到低功耗岛,从而维持平台整体的能效表现。

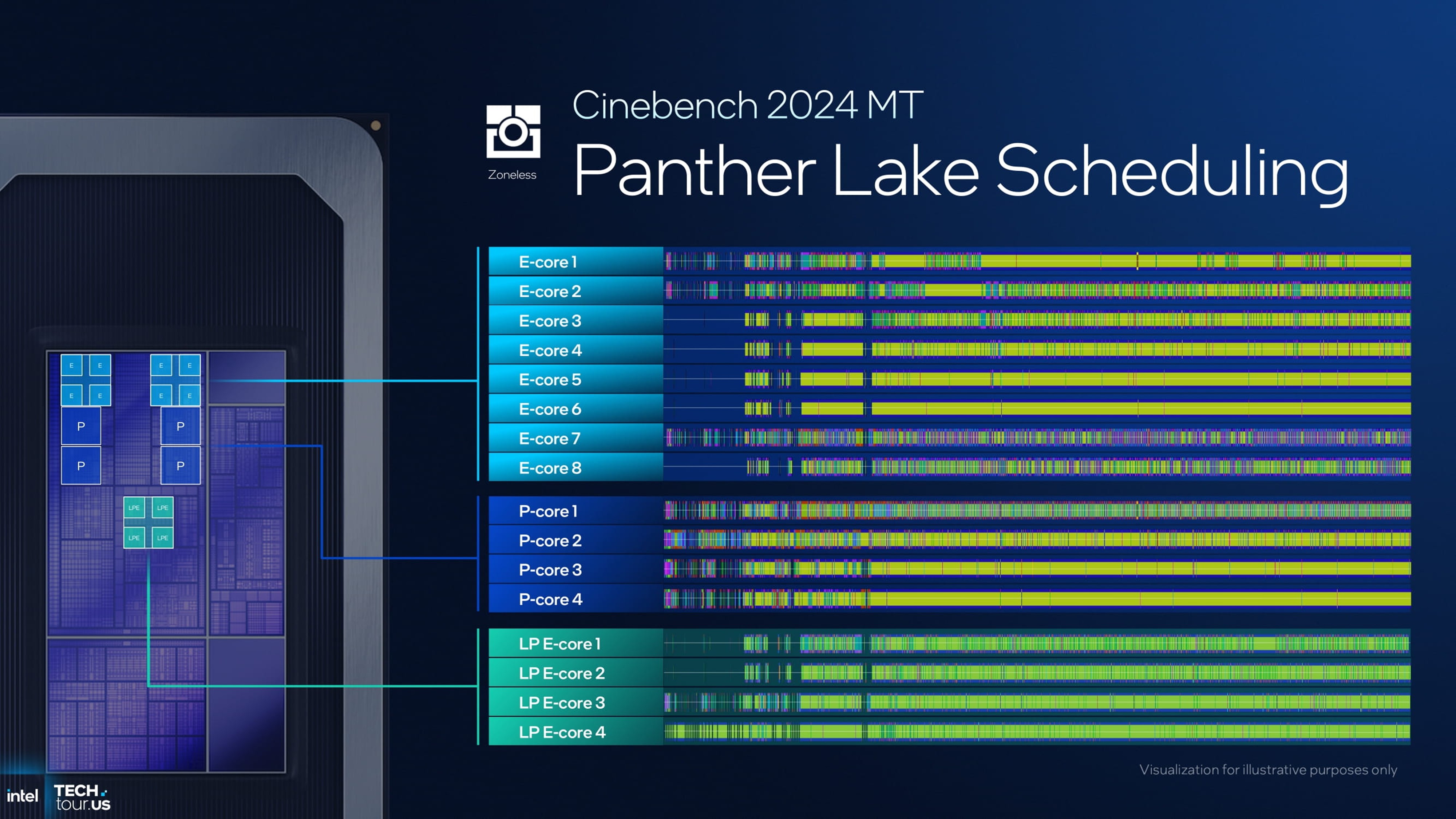
不过,Panther Lake 的核心分层架构较以往更加复杂(例如 484 结构属于三层级体系),这自然引出了任务调度上的技术挑战。为此,英特尔在该架构中引入了新一代的 Thread Director 线程调度机制。
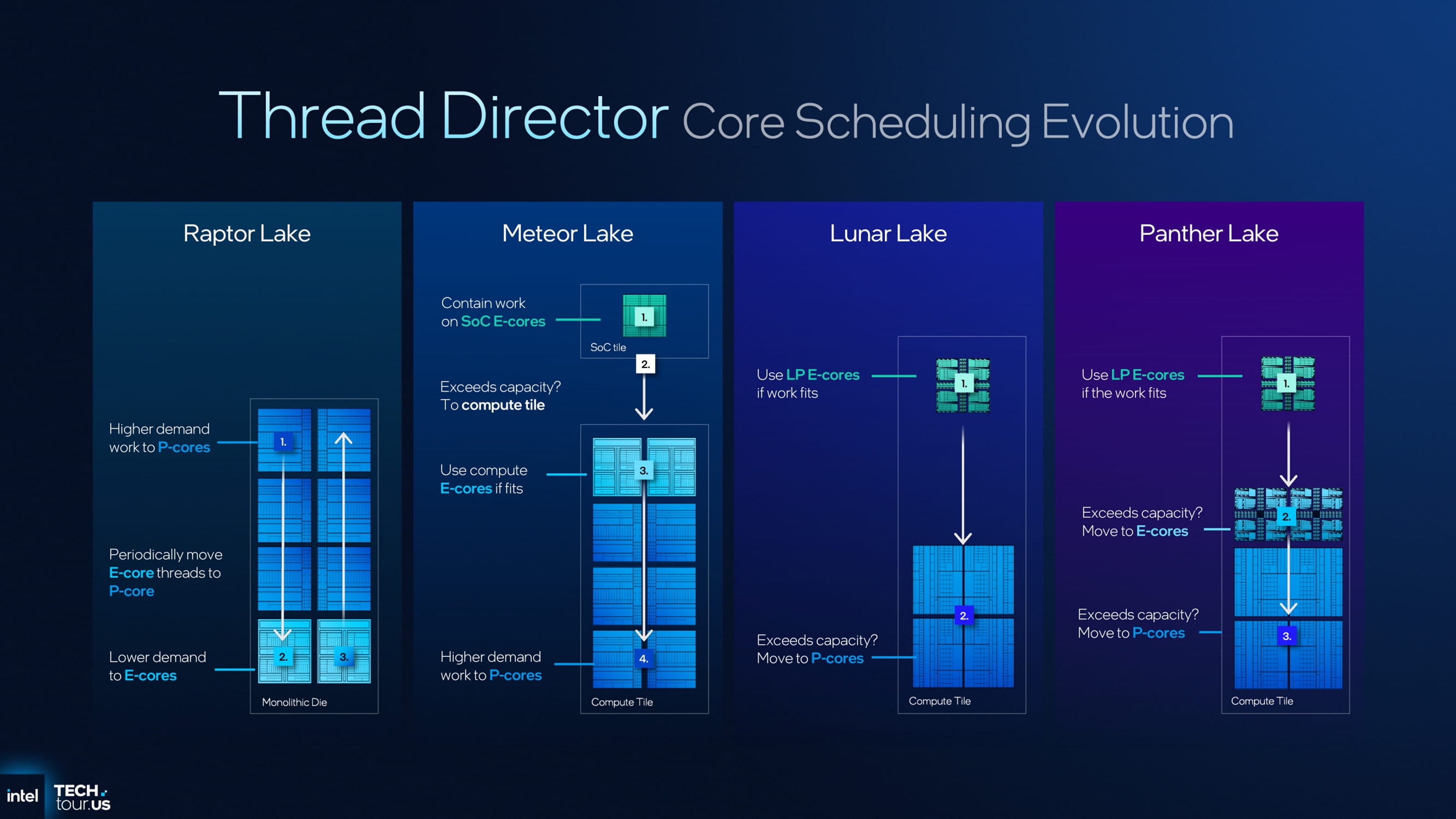
新版 Thread Director 在优先级算法上进行了更新:
- 优先将轻负载任务分配给 LP E-core;
- 当运算需求增加时,逐步启用 E-core;
- 在高性能需求下,最后才启动 P-core。
在英特尔提供的展示示例中,这一机制应用于如 Microsoft Teams 与 Microsoft Effects Package 之类的多应用并行场景。借助 Thread Director 的分级调度,几乎所有后台负载(视频会议、摄像头处理、实时特效计算等)都被固定在能效核心上运行,从而显著降低系统功耗。

根据现场演示数据,在类似于“办公会议”这样的综合使用场景中——同时运行 Teams、Excel、PPT 以及多个网页标签页与视频窗口——整机功耗仅 7.69 瓦,较 Lunar Lake 的8.36W更低,也远低于 Arrow Lake的11.5W。同负载下,整机能耗优化相当明显。

当然,也不能全信——Lunar Lake 的续航优势是它采用了 集成式 PMIC 电源管理设计,能够显著降低待机idle功耗。而 Panther Lake 延续传统 DLVR 供电,idle功耗可能会更高。换言之,这种“低功耗展示”更能代表平台优化方向,而非实际续航的完整指标。
此外,英特尔在能耗策略上还拓展了一种新的 E-core 优先调度模型,旨在进一步释放 GPU 的潜能。在游戏场景下,CPU 会主动降低前台占用,让更多功率预算分配给 GPU,以实现更高的图形性能。
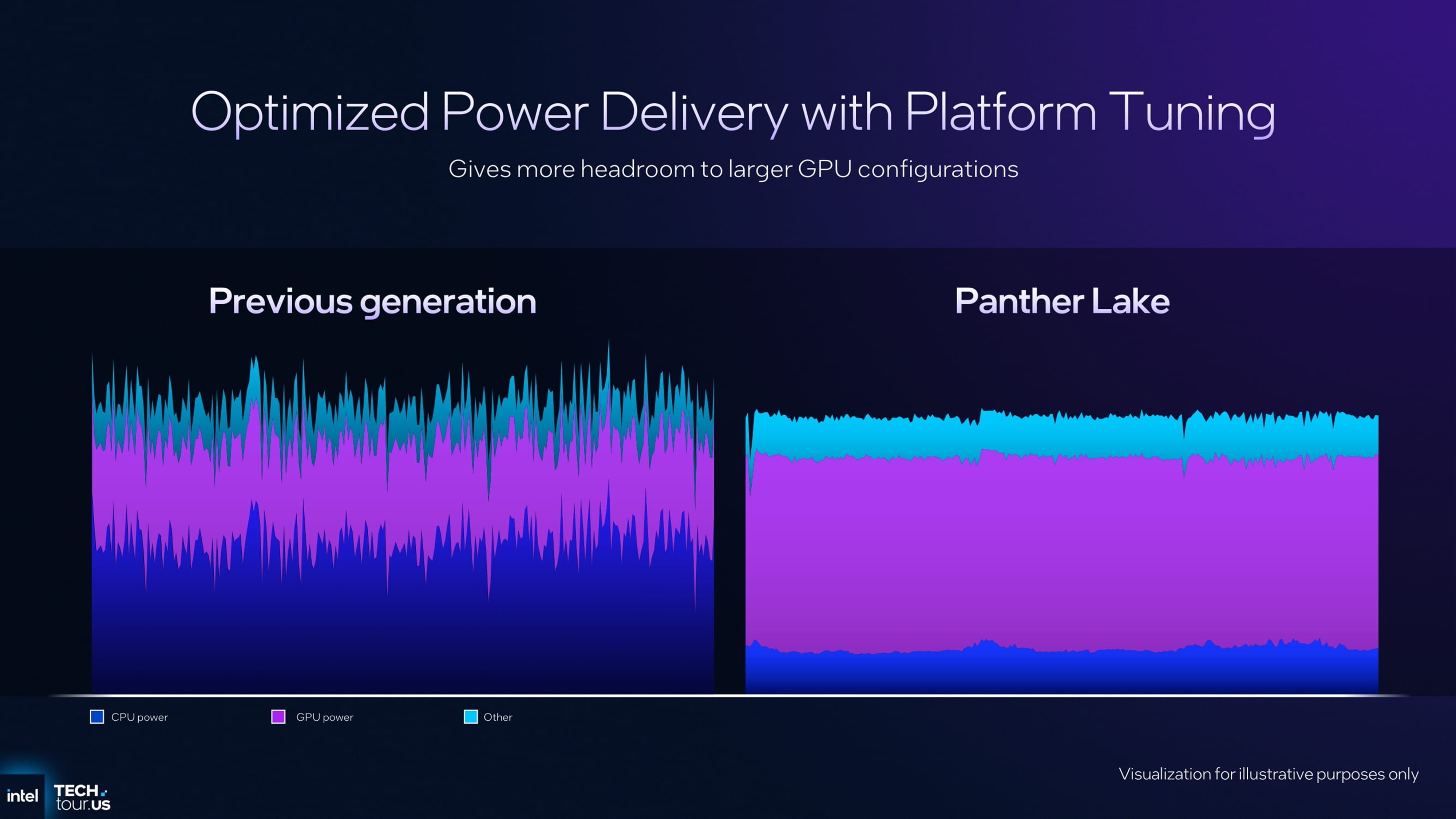
这样的架构理念对 掌机类设备(Handheld PC) 尤为有利——在功耗高度受限的条件下,CPU 消耗越低,就能为 GPU 提供更多的功率空间。这一方案早在 Lunar Lake 平台中已有实践,英特尔也曾展示过相关原型。在典型的 17W TDP 场景 下,系统可显著提升最低帧表现(1% Low FPS),提升流畅度。
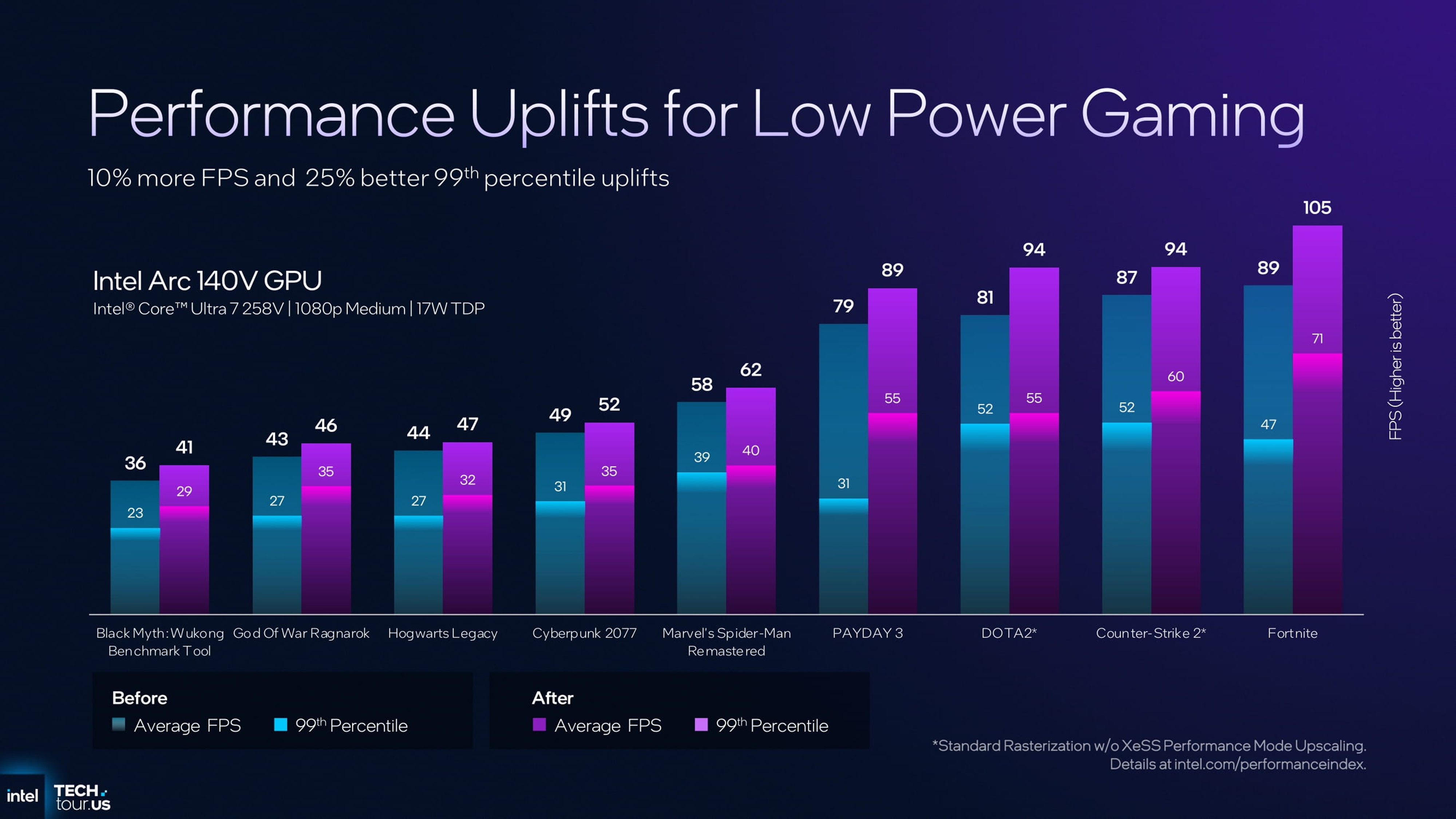
在 Panther Lake 平台中,这种机制同样得到延续。

12 Xe 核显版本(PTL 484+12Xe) 也可以用于掌机系统,其整体调度能力与能耗优化表现更为突出,因此在后续的掌机设计中,英特尔仍计划以该版本作为主要方案,而非沿用 Lunar Lake 的 404 型号。
NPU 架构与 AI 能力
对于用户而言,这一代 Panther Lake 在 AI 运算单元(NPU) 上的变化,同样是值得关注的重点之一。
Panther Lake 的 NPU 从 NPU 4 升级为 NPU 5,但从架构层面来看,有升级。换句话说,这一代 NPU 的性能提升没有提升,Luanr Lake是50TOPS,Panther Lake也是50 TOPS,几乎一样。

造成这种“性能持平”的原因在于当前业界的 Copilot+ PC 认证标准。微软针对支持其 Copilot+ 功能的硬件设定了 NPU 算力门槛——必须达到 40 TOPS(每秒 40 万亿次操作) 才能获得该认证。
对于英特尔而言,既然 Panther Lake 的整合 NPU 已经足以满足这一标准,就没有必要盲目继续堆高算力。在短期内,竞品(包括 AMD)在未来两年内的 NPU 性能也维持在 约 50 TOPS 左右,因此在没有竞争压力的情况下,过度提升 NPU 性能并不会带来显著的市场收益。

因此,英特尔在 Panther Lake 的 NPU 设计中采取了更务实的取舍策略:
- MAC Array(矩阵乘加阵列) 的规模扩大一倍,以适应更高的理论运算密度;
- 同时,NCE(Neural Compute Engine,神经计算单元) 的数量从原先的六个减少至三个,整体体系更为紧凑。
这样的调整使得 NPU 模块在保持相同算力输出的同时,减少了 约 40% 的硅片面积占用。由于近年来 NPU 在芯片封装中逐渐成为“大户”,这一空间节省直接降低了芯片制造与封装成本。
Panther Lake 为了 有限硅面积与设计预算 下实现“够用即好”的方案——既保证通过 Copilot+ PC 的认证,又避免 NPU 模块过度侵占 CPU 与 GPU 的面积资源。
这种“适度优化”也符合当前 AI PC 市场的应用实际:在多数主流使用场景中,软件生态仍在建设阶段,尚未充分利用超过 40 TOPS 的本地 AI 加速性能。因此,控制 NPU 尺寸、提高面积利用率反而是更合理的选择。
以上就是关于英特尔Panther Lake酷睿Ultra 300H系列的全部解读了。

![]()
[…] 本网站专栏作家金猪升级包撰文,独家详细解读英特尔Panther Lake酷睿Ultra 300H产品线,可以点击此处阅读全文。 […]
[…] 关于英特尔Panther Lake酷睿Ultra 300H的详细解析,可以阅读产品线解读。 […]